
Abstract
Multi-view ensemble learning has the potential to address issues related to the high dimensionality of data. It attempts to utilize all the relevant only discarding the irrelevant features. The view of a dataset is the sub-table of the training data with respect to a subset of the feature set. The problem of discarding the irrelevant features and obtaining subsets of the relevant features is useful for dimension reduction and dealing with the problem of having fewer training examples than even the reduced set of relevant features. A feature set partitioning resulting in the blocks of relevant features may not yield multiple-view-based classifiers with good classification performance. In this work the optimal feature set partition approach has been proposed. Further, the ensemble learning from views aims to maximize the performance of the classifier. The experiments study the performance of random feature set partitioning, attribute bagging, view generation using attribute clustering, view construction using genetic algorithm and OFSP proposed method. The blocks of relevant feature subsets are used to construct the multi-view classifier ensemble using K-nearest neighbor, Naïve Bayesian and support vector machine algorithm applied to sixteen high-dimensional data sets from UCI machine learning repository. The performance parameters considered for comparison are classification accuracy, disagreement among the classifiers, execution time and percentage reduction of attributes.







Similar content being viewed by others

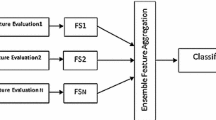
References
Kumar V, Minz S (2013) Mood classification of lyrics using SentiWordNet. In: ICCCI-2013, India, IEEE Xplore, pp 1–5
Ando RK, Zhang T (2007) Two-view feature generation model for semi-supervised learning. In: ICML
Xu C, Tao D, Xu C (2013) A survey on multi-view learning. Learning (cs.LG)
Kakade SM, Foster DP (2007) Multi-view regression via canonical correlation analysis. In: COLT
Yu S, Krishnapuram B, Rosales R, Steck H, Rao RB (2007) Bayesian co-training. In: NIPS
Kudo M, Sklansky J (1997) A comparative evaluation of medium and large-scale feature selectors for pattern classifiers. In: Proceeding of the 1st international workshop on statistical techniques in pattern recognition. Czech Republic, Prague, pp 91–96
Bluma AL, Langley P (1997) Selection of relevant features and examples in machine learning. In: Greiner R, Subramanian D (eds) Artificial intelligence on relevance, artificial intelligence, vol 97, pp 245–271
Kumar V, Minz S (2014) Multi-view ensemble learning for poem data classification using SentiWordNet. In: 2nd international conference on advanced computing, networking, and informatics (ICACNI-2014), Smart Innovation, Systems and Technologies, vol 27. Springer, Berlin, pp 57–66
Minz S, Kumar V (2014) Reinforced multi-view ensemble learning for high dimensional data classification. In: International conference on communication and computing (ICC-2014), Elsevier
Brefeld GC, Scheffe T (2005) Multi-view discriminative sequential learning. In: Machine learning, ECML 2005, pp 60–71
Ben-Bassat M (1982) Pattern recognition and reduction of dimensionality. In: Krishnaiah PR, Kanal LN (eds) Handbook of statistics-II. North Holland, pp 773–791
Almuallim H, Dietterich TG (1994) Learning boolean concepts in the presence of many irrelevant features. Artif Intell 69(1–2):279–305
Devijver PA, Kittler J (1982) Pattern recognition: a statistical approach. Prentice Hall, London
Hall MA (2000) Correlation-based feature selection for discrete and numeric class machine learning. In: Proceedings of the 17th international conference on machine learning, pp 359–366
Ho TK (1998) Nearest neighbors in random subspaces. In: Proceeding of the second international workshop on statistical techniques in pattern recognition. Sydney, Australia, pp 640–648
Bay S (1999) Nearest neighbor classification from multiple feature subsets. Intell Data Anal 3(3):191–209
Bryll R, Gutierrez-Osunaa R, Quek F (2003) Attribute bagging: improving the accuracy of classifier ensembles by using random feature subsets. Pattern Recognit 36:1291–1302
Wu QX, Bell D, McGinnity M (2005) Multi-knowledge for decision-making. Knowl Inf Syst 7:246–266
Hu QH, Yu DR, Wang MY (2005) Constructing rough decision forests. In: Slezak D et al (eds) RSFDGrC 2005, LNAI 3642. Springer, Berlin, pp 147–156
Bao Y, Ishii N (2002) Combining multiple K-nearest neighbor classifiers for text classification by reducts. In: Proceedings of 5th international conference on discovery science, LNCS 2534. Springer, Berlin, pp 340–347
Cunningham P, Carney J (2000) Diversity versus quality in classification ensembles based on feature selection. In: de Mntaras RL, Plaza E (eds) Proceedings of ECML 2000, 11th European conference on machine learning, Barcelona, Spain, LNCS 1810. Springer, Berlin, pp 109–116
Zenobi G, Cunningham P (2001) Using diversity in preparing ensembles of classifiers based on different feature subsets to minimize generalization error. In: Proceedings of the European conference on machine learning
Rokach L, Maimon O, Arad O (2005) Improving supervised learning by sample decomposition. Int J Comput Intell Appl 5(1):37–54
Rodriguez JJ (2006) Rotation forest: a new classifier ensemble method. IEEE Trans Pattern Anal Mach Intell 20(10):1619–1630
Rokach L (2010) Pattern classification using ensemble learning. In: Series in machine perception and artificial intelligence, vol 75. World Scientific, Singapore
Kusiak A (2000) Decomposition in data mining: an industrial case study. IEEE Trans Electron Packag Manuf 23(4):345–353
Gama J (2000) A linear-bayes classifier. In: Monard C (ed) Advances on artificial intelligence—SBIA 2000. LNAI 1952. Springer, Berlin, pp 269–279
Breiman L (1996) Bagging predictor. Mach Learn 24:123–140
Ho TH (1998) The random subspace method for constructing decision forest. IEEE Trans Pattern Anal Mach Intell 20(8):832–844
Sun S, Jin F, Tu W (2011) View construction for multi-view semi-supervised learning. In: Advances in neural networks-ISNN 2011, pp 595–601
Di W, Crawford M (2012) View generation for multi-view maximum disagreement based active learning for hyperspectral image classification. IEEE Trans Geosci Remote Sens 50(5)
Tumer K, Ghosh J (1996) Error correlation and error reduction in ensemble classifiers. Connect Sci 8(3–4):385–404
Liao Y, Moody J (2000) Constructing heterogeneous committees via input feature grouping. In: Solla SA, Leen TK, Muller K-R (eds) Advances in neural information processing systems, vol 12. MIT Press, Cambridge
Rokach L (2008) Mining manufacturing data using genetic algorithm-based feature set decomposition. Int J Intell Syst Technol Appl 4(1):57–78
Kohavi R, John GH (1997) Wrappers for feature subset selection. Artif Intell 97(1–2):273–324
Kumar V, Minz S (2014) Feature selection: a literature review. Smart Comput Rev 4(3):211–229
Liu H, Motoda H (1998) Feature selection for knowledge discovery and data mining. Kluwer, London
Tao D, Tang X, Li X, Wu X (2006) Asymmetric bagging and random subspace for support vector machines-based relevance feedback in image retrieval. IEEE Trans Pattern Anal Mach Intell 28(7):1088–1099
De Sa V, Gallagher P, Lewis J, Malave V (2010) Multi-view kernel construction. Mach Learn 76:47–71
Szendmak S, Shawe-Taylor J (2007) Synthesis of maximum margin and multi-view learning using unlabeled data. Neurocomputing 70:1254–1264
Rosenberg D, Sindhwani V, Bartlett P, Nuyogi P (2009) Multi-view point cloud kernels for semi-supervised learning. IEEE Signal Process Mag 145:145–150
Xu Z, Sun S (2010) An algorithm on multi-view adaboost. Lect Note Comput Sci 6443:332–402
Dasgupta S, Littman ML, McCallum D, Mitchell T, Nigam K, Slattery S (2002) Pac gereralization bounds for co-training. Adv Neural Inf Process Syst 1:375–382
Ho TK (1998) The random subspace method for constructing decision forests. IEEE Trans Pattern Anal Mach Intell 20(8):832–844
Tsymbal A, Pechenizkiy M, Cunningham P (2005) Diversity in search strategies for ensemble feature selection. Inf Fusion 6(1):83–98
Gunter S, Bunke H (2004) Feature selection algorithms for the generation of multiple classifier systems. Pattern Recognit Lett 25(11):1323–1336
Di W, Crawford MM (2012) View generation for multiview maximum disagreement based active learning for hyperspectral image classification. IEEE Trans Geosci Remote Sens 99:1–13
Rokach L (2008) Genetic algorithm-based feature set partitioning for classification problems. Pattern Recognit 41(5):1676–1700
Muslea I, Minton S, Knoblock CA (2002) Adaptive view validation: a first step towards automatic view detection. In: Machine learning-international workshop then conference. Citeseer, pp 443–450
Christoudias CM, Urtasun R, Darrell T (2008) Multi-view learning in the presence of view disagreement. In: Proceedings of the 24th conference on uncertainty in artificial intelligence
Christoudias CM, Urtasun R, Kapoorz A, Darrell T (2009) Co-training with noisy perceptual observations. In: Computer vision and pattern recognition, 2009. CVPR, 2009, IEEE conference on, pp 2844–2851. IEEE
Liu C, Yuen PC (2011) A boosted co-training algorithm for human action recognition. IEEE Trans Circuits Syst Video Technol 21(9):1203–1213
Brown G, Wyatt J, Harris R, Yao X (2005) Diversity creation methods: a survey and categorisation. Inf Fusion 6(1):5–20
Margineantu D, Dietterich T (1997) Pruning adaptive boosting. In: Proceedings of fourteenth international conference machine learning, pp 211–218
Kuncheva L, Whitaker C (2003) Measures of diversity in classifier ensembles and their relationship with ensemble accuracy. Mach Learn, pp 181–207
Sun S, Jin F (2011) Robust co-training. Int J Pattern Recognit Artif Intell 25:1113–1126
Xu Z, Sun S (2010) An algorithm on multi-view adaboost. Lect Note Comput Sci 6443:355–362
Opitz D, Shavlik J (1996) Generating accurate and diverse members of a neural-network ensemble. In: Touretzky DS, Mozer MC, Hasselmo ME (eds) Adv Neural Inf Process Syst, vol 8. The MIT Press, Cambridge, pp 535–541
Buntine W (1990) A theory of learning classification rules. Doctoral Dissertation, School of Computing Science University of Technology. Sydney, Australia
Wolpert DH (1992) Stacked generalization. Neural Netw 5:241–259
Chan PK, Stolfo SJ (1993) Toward parallel and distributed learning by meta-learning. In: AAAI Workshop in knowledge discovery in databases, pp 227–240
Chan PK, Stolfo SJ (1997) On the accuracy of meta-learning for scalable data mining. J Intell Inf Syst 8:5–28
Hodges JL, Lehmann EL (1962) Rank method for combination of independents experiment analysis of variance. Ann Math Stat 33:482–497
Garcia S, Herrera F (2008) An extension of statistical comparison of classifiers over multiple datasets for all pair wise comparisons. Mach Learn Res 09:2677–2694
Steelv RGD (1959) A multiple comparison sign test: treatments versus control. J Am Stat Assoc 54:767–714
Doksum K (1967) Robust procedures for some linear models with one observation per cell. Ann Math Stat 38:878–883
Abramowitz M (1974) Handbook of mathematical functions. In: With formulas, graphs, and mathematical tables. Dover Publication, NY
Derrac J, Garcia S, Molina D, Herrera F (2011) A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithm. Swarm Evol Comput 1:3–18
Dunn OJ (1961) Multiple comparisons among means. J Am Stat Assoc 56:52–64
Holm S (1979) A simple sequentially rejective multiple test procedure. Scand J Stat 6:65–70
Holland BS, Copenhaver MD (1987) An improved sequentially rejective Bonferroni test procedure. Biometrics 43:417–423
Finner H (1993) On a monotonicity problem in step-down multiple test procedures. J Am Stat Assoc 88:920–923
Garcia S, Fernandez A, Luengo J, Herrera F (2010) Advanced non-parametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: experimental analysis of power. Inf Sci 18:2044–2064
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kumar, V., Minz, S. Multi-view ensemble learning: an optimal feature set partitioning for high-dimensional data classification. Knowl Inf Syst 49, 1–59 (2016). https://doi.org/10.1007/s10115-015-0875-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-015-0875-y