
The analytics team at the Wikimedia Foundation is excited to release a new dataset for our community and the world: unique devices. This is a new way for us to estimate how many people read Wikimedia projects on the web on a monthly and daily basis. Our measure is an estimate because we are counting devices, rather than visitors, and some people use more than one device to access the web (a mobile phone and a desktop, for example) and some people share computers. While unique devices does not equal unique visitors, it is a good proxy for that metric, meaning that a major increase in the number of unique devices comes likely from an increase in visitors.
In developing this dataset, we looked critically at previous methods we’ve used to measure reach. We knew we wanted to count unique readers and we wanted to do it in a manner that treated user privacy and security as a priority. In response, we came up with a novel, light-touch way of estimating unique device counts for Wikimedia projects. In this post, we’ll share how we used to estimate unique readers, why we needed to change, and how we’re doing it now.
We invite you to explore this new dataset and hope it’s helpful for the Wikimedia community in better understanding our projects. This data can help measure how large is the reach of Wikimedia projects on the web. For example, we have estimated more than 600 million unique devices in January 2016 on English wikipedia alone (adding desktop and mobile). We expect this number to vary seasonally greatly as numbers for November were around 440 million. Still, English Wikipedia is the largest project, with three times as many devices as the next most popular project, Spanish Wikipedia.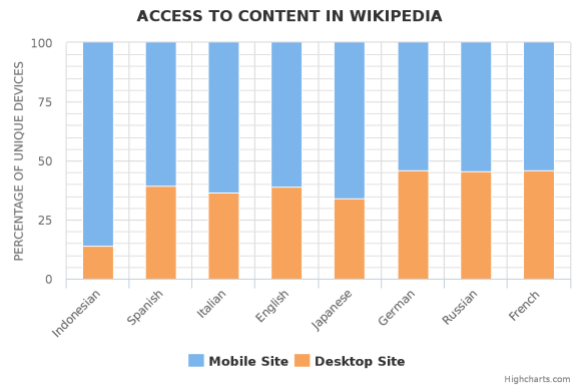
Photo by Nuria Ruiz, CC BY-SA 3.0.
How we used to count unique web readers
Users of Wikimedia projects don’t need to login to access content, so unlike other major websites, we can’t count unique readers via accounts. Since 2009, the Wikimedia Foundation used comScore to report data about unique visitors. The relationship was pro bono, and we benefited from having an estimate of our traffic and ranking among other websites. In January 2016, however, we decided to stop reporting comScore numbers because of certain limitations in the methodology.
ComScore’s strength is in measuring traffic from desktop, and we found that this data was less accurate for mobile devices, which represent a significant portion of Wikimedia traffic. This could be addressed by installing tracking beacons on our sites that stream data back to comScore, but we didn’t do this because we aim to protect user privacy and security, and, we do not share user data with third parties not subjected to the same standards.
With the unique devices dataset, we’ve been able to quantify the shift to mobile across all projects. In almost all Wikimedia projects, more than half of our unique devices are accessing content using the mobile sites. That means that in terms of usage, mobile represents more than half of Wikimedia projects’ overall usage, which makes an accurate measurement for mobile traffic a high priority. In some projects, the mobile access represents a much higher percentage. For example, 85% of usage of Indonesian Wikipedia is happening in the mobile site rather than desktop .
How we count unique readers now. Privacy by Design.
Developing our own way to count allows us to be certain about the meaning behind the numbers, to understand how the approach holds up in practice, and to share the high-level numbers with the wider community. Our goal when we started was to acquire greater value from usage data while reducing the risk of data misuse (i.e. privacy risks).
Imagine we want to count the number of patients a doctor has in a month without disclosing sensitive data about medical visits of specific patients. An intrusive way to do this would be keeping a list of users that came to the doctor’s office that month. For example:
- Alicia
- Susana
- Maria
A list like that holds a lot of personal information. Alicia might not be very fond of everybody knowing that she went to the doctor on March 2016. Another way to to count patients while preserving their anonymity would be making a list like:
- First Patient
- Second Patient
- Third Patient
However, in this case there is no way to differentiate between the First and Third patient once they have left the doctor’s office. The problem is that we want to count patients that come in a given time period (for example, a month), but we do not want to identify patients individually. At the same time, we need to be able to know who has already come to the office that month so we don’t count them twice.
What we do: when patients leave the doctor’s office, we hand them slips that print the date in which they came into the office last. In our example, the slip says: “Last-Time-Visited: February 17th”. How is this useful? Let’s say we are counting unique patients of the doctor office in March: anyone that comes into the doctor’s office without a time slip is a new patient for the month (they have not been at the doctor’s office before at all, we are giving slips to everyone). Anyone that comes with a slip that says “Last-Time-Visited: February 17th” when we are in March should also be counted as a unique patient for the month of March as they were at the doctor’s office last on February. For our counting to be accurate we need to update the time information to note that we have seen this patient already in March, so before patient leaves we update their slip and give them a new one that says “Last-Time-Visited: March 15th”.
The careful reader would have noticed that we do not need to print the day on the timeslip—to count monthly users is sufficient with just printing the month. Now, printing the date more precisely allow us to count daily uniques with the same methodology. If we are counting, say, the number of patients on March 15th anyone coming without a time slip needs to be counted towards the daily toll (patient has not been at the doctor’s office before), anyone with a time slip with a date before March 15th should be counted too. If a patient comes twice to the office on March 15th, we will not count them twice as we only update their time slip once a day, the second time the patient shows up the slip already says “Last-Time-Visited: March 15th”.
Using this strategy, we have successfully implemented regular unique devices counting in a manner that treats user privacy and security as a priority. We believe that by designing with privacy and security in mind, we can develop products and services that benefit our users, the community and staff alike.
Limitations
As with any method, unique devices has some limitations. It only counts the number of unique devices used to access Wikipedia. This leaves room for duplication: when a user looks at a Wikipedia page on their desktop and mobile phone, we will be counting two devices.
Bots
Things got a little complicated when we tried to implement this original idea. We set a cookie in every browser request that comes into a Wikimedia project with the value of our time slip: “Last-Access: February 17th”. The cookie is set to expire every 30 days and its value is refreshed in every request. When we started counting we realized that the number of requests with no cookie seemed too high. In hindsight, this makes sense. Wikipedia gets a lot of automated bot traffic that does not accept cookies. In our analogy above, the bots are the people that come into the doctor’s office with no time slip. With our methodology, we cannot tell doctor’s patients from other people that are just walking by into the office to, say, deliver a package. Solving this last problem was not trivial given that our bot detection framework is somewhat ”rustic”. The technical solutions we used are documented at length here and here.
Smaller Projects
We looked at data regarding unique devices for all Wikimedia projects and it was fairly obvious that for small projects (those with fewer than 1000 daily uniques), data for daily uniques was too sparse to be meaningful. Therefore, our public datasets only contain data for projects with more than 1000 uniques.
Drawbacks
While our approach to counting uniques reduces the risk of data misuse, it has some drawbacks from an analytic perspective. For example, we cannot use the methodology to split up our user-base for an A/B test. We are also (purposely) not counting users who browse Wikimedia projects with their cookies off. And lastly, we know our methodology somewhat under-reports numbers, but we are okay with that.
I want to use this same methodology to count uniques on my site. Can I?
You sure can. The code that sets cookies is deployed to our varnish caching servers rather than the MediaWiki code and it is somewhat dry. You can find it on github. Now, implementing the same logic in php/python/java/you-name-it should be easy.
Nuria Ruiz, Software Engineer
Madhumitha Viswanathan, Software Engineer
Aaron Halfaker, Senior Research Scientist
Wikimedia Foundation
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation