With the release of pgvector 0.6, there is a major update in the index-building capability of HNSW – i.e. Parallel Index Build.
Thanks to Andrew Kane and Heikki Linnakangas for this feature.
What is Parallel Index Build?
Parallel Index Build refers to the capability to build indexes using parallel processing. In simpler terms, it means that multiple workers or threads can be utilized simultaneously to create an index, which can significantly speed up the index creation process.
When performing an index build operation, PostgreSQL can divide the work among multiple parallel workers, each responsible for building a portion of the index.
This parallelization allows for better utilization of system resources, such as CPU cores and memory, resulting in faster index creation times, especially for large tables. So this is a faster way to build the indexes as compared to traditional single-threaded builds.
In a benchmark run by team Stormatics, it is evident that parallel index build can be 80% faster than traditional single thread index building.
max_parallel_maintenance_workers
It is a configuration parameter in PostgreSQL that determines the maximum number of parallel workers that can be used for maintenance operations.
Maintenance operations in PostgreSQL include tasks like index creation, vacuuming, and other background processes that help optimize and maintain the database. These operations can benefit from parallel executions.
By setting the value of “max_parallel_maintenance_workers”, you can control the maximum number of parallel workers that can be utilized specifically for maintenance operations. This allows you to allocate resources and balance the workload between regular queries and maintenance tasks.
NOTE: max_parallel_maintenance_workers operates within the overall limit set by max_worker_processes. The total number of worker processes running concurrently cannot exceed max_worker_processes.
If max_worker_processes is set to 16 and max_parallel_maintenance_workers is set to 8, PostgreSQL can have a maximum of 8 worker processes dedicated to background maintenance tasks at any given time. The remaining 8 worker processes would be available for other tasks like client connections.
Recommended Reading: Understand Indexes in pgvector
Benchmark methodology
Mechanism
We conducted tests using varying values for max_parallel_maintenance_workers, including 0, 2, 4, 6, and 8.
Test environment
- Cloud Provider: AWS
- EC2 Instance Type: t2.2xlarge
- CPU Configuration: 8 cores
- RAM Allocation: 32 GB
- Hard Drive Capacity: 500 GB
- Hard Drive Performance: 3000 IOPS
- Operating system: Ubuntu 22.04 LTS
- Filesystem: ext4
Database versions and parameter configurations
- PostgreSQL: 16.2
- maintenance_work_mem = 4GB
- shared_buffers = 8GB
- pgvector: 0.6.1
- m = 16
- ef_construction = 64
Benchmarking tool
We have used ann-benchmarks and the dataset used was dbpedia-openai-1000k-angular we have locally run this benchmark instead of using docker with –local switch
sudo python3 run.py --dataset dbpedia-openai-1000k-angular --runs 1 --local --algorithm pgvector --definitions ann_benchmarks/algorithms/pgvector
Results
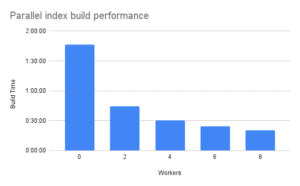
| Workers | 0 | 2 | 4 | 6 | 8 |
| Build Time | 1:46:18 | 0:44:33 | 0:30:23 | 0:24:18 | 0:20:32 |
In the above statistics, the parallel index build emerges as the clear victor. We managed to slash the index build time from 1 hour and 46 minutes to a mere 20 minutes with the aid of 8 parallel workers. This performance could be further enhanced by employing a higher-specification instance and increasing the number of parallel workers.
Stay tuned for upcoming benchmarks, where we’ll subject pgvector to stress tests.
Continue reading our blog posts below, or reach out if you have any questions using our contact form.