Am 14. Mai 2024 ist es soweit: Die Empfehlungen “Offene KI für alle!” werden als feierlicher Abschluss des Forums Offene KI in der Bildung bei Wikimedia Deutschland präsentiert. Dabei wird die Bildungswissenschaftlerin und Pädagogin Nele Hirsch mit folgenden Bildungs- und Digitalpolitiker*innen zu den Empfehlungen ins Gespräch kommen:
Dr. Holger Becker, MdB, SPD-Fraktion, Mitglied im Ausschuss für Digitales und im Ausschuss für Bildung und Forschung
Anke Domscheit-Berg, MdB, digitalpolitische Sprecherin DIE LINKE im Bundestag
Maximilian Funke-Kaiser, MdB, digitalpolitischer Sprecher der FDP-Bundestagsfraktion
Sabine Grützmacher, MdB, Fraktion Bündnis 90/Die Grünen, Digitalpolitikerin und Bildungsinformatikerin
Franziska Hoppermann, MdB, CDU/CSU-Fraktion, Mitglied im Ausschuss für Digitales
Ziel ist es, Maßnahmen seitens der Politik zu ermitteln, wie der Einsatz und die Weiterentwicklung von KI in der Bildung offen und gemeinwohlorientiert gestaltet werden können. Es sollen möglichst konkrete Vorschläge diskutiert werden, wie die Empfehlungen in die Umsetzung gebracht werden können.
Alle Interessierten sind herzlich eingeladen, an der Veranstaltung teilzunehmen (vor Ort in Berlin oder digital), Fragen an die anwesenden Politiker*innen zu stellen und mitzudiskutieren. Die Anmeldung zur Veranstaltung ist hier möglich.
Worum geht es in den Empfehlungen?
Generative KI und vor allem ChatGPT hat an vielen Stellen Einzug in das deutsche Bildungssystem gehalten und sorgt(e) für große Fragezeichen auf Seiten von Lehrpersonen, Bildungsinstitutionen und Bildungspolitik. Nahezu alle Bundesländer haben inzwischen eigene Leitfäden für Lehrpersonen im Umgang mit KI veröffentlicht. Jetzt gilt es, auf bestehende Ansätze der Länder aufzubauen, Erfahrungswerte aus der Praxis zusammenzubringen und politische Kräfte so zu bündeln, dass wegweisende Rahmenbedingungen geschaffen werden, die eine “Offene KI für alle!” ermöglicht.
Dafür hat Wikimedia Deutschland e. V. in Zusammenarbeit mit Nele Hirsch das Forum Offene KI in der Bildung geschaffen, um im Austausch mit verschiedenen Expert*innen aus der Bildungslandschaft, Empfehlungen auf den Weg zu bringen, die die Perspektive von Offenheit und Gemeinwohlorientierung bei KI stärker in den Blick nehmen. Mit insgesamt zehn Empfehlungen richten wir uns deshalb dezidiert an Bildungs- und Digitalpolitiker*innen auf Bundes- und Landesebene. Die Empfehlungen decken dabei die folgenden Bereiche ab: 1. Infrastruktur und Zugang, 2. Offene Bildungspraxis, 3. Grundrechte im digitalen Raum.
Wie sind die Empfehlungen entstanden?
Entstanden sind die Empfehlungen zwischen November 2023 und Mai 2024 in mehreren kollaborativen Schreibwerkstätten. Ausgangspunkt dafür war der im Frühjahr 2023 verfasste Aufruf “Künstliche Intelligenz, Offenheit und Pädagogik” der Initiative OE/AI, der auf dem Barcamp edunautika zu zeitgemäßer Pädagogik im digitalen Wandel verfasst wurde. Die Beteiligten kamen aus den folgenden Bildungssektoren: Dozierende aus Universitäten und Hochschulen, Lehrkräfte allgemeinbildender und beruflicher Schulen, Lehrpersonen aus Erwachsenenbildungsinstituten, Mitarbeitende aus Fortbildungsinstituten der Bundesländer, aus politischen Stiftungen sowie Bildungsstiftungen und -organisationen.
Mit der Veröffentlichung der Empfehlungen fängt die Diskussion erst richtig an. Dafür sind wir in den nächsten Wochen und Monaten bei verschiedenen Konferenzen. Den Auftakt bildete am 24. und 25. Mai die Konferenz Bildung Digitalisierung. Hier gaben Sarah-Isabella Behrens und Anne-Sophie Waag von Wikimedia Deutschland e. V. gemeinsam mit Nele Hirsch im Rahmen eines Meet-Ups einen Sneak Peak in die Empfehlungen. Das große Interesse der Teilnehmenden und die angeregte Diskussion zeigten, dass das Thema viele Menschen in der Bildung aktuell beschäftigt und die Empfehlungen einen Nerv treffen.
In den kommenden Wochen werden wir bei folgenden Veranstaltungen über die Erkenntnisse und Erfahrungen aus dem Forum Offene KI in der Bildung sprechen und freuen uns, hier mit Ihnen und Euch in den Austausch zu kommen:
re:publica, Berlin, 27. Mai, ab 15:00 – Session “Who cares about AI in education? Warum wir eine offene KI für die Bildung fordern, welche Empfehlungen wir gemeinschaftlich entwickelt haben und wie du dich einbringen kannst!”
University:Future Festival, Leipzig-Stage, 5. Juni, 15:40 Uhr – Session “Die KI von morgen? Offen und gemeinwohlorientiert!”
Nach Veröffentlichung der Empfehlungen “Offene KI für alle!” stehen diese hier unter freier Lizenz für alle Interessierten zur Verfügung: Zum Herunterladen, Teilen, Weiterentwickeln und Weiterdiskutieren!
Wenn der Staat langfristig handlungs- und strategiefähig sein möchte, muss er dringend die notwendige Basis für eine moderne Verwaltung legen. Dafür ist eine solide Daten- und IT-Grundlage auf dem Stand der Technik unerlässlich – sowohl um die Potenziale von Open Data zu nutzen als auch für den Einsatz künstlicher Intelligenz. Unter der Schirmherrschaft von Nadine Schön MdB (stellvertretende Vorsitzende der CDU/CSU Bundestagsfraktion und Mitglied im Ausschuss für Digitales) ging es beim parlamentarischen Frühstück deswegen um die Fragen: Welche Rahmenbedingungen müssen Politikschaffende für den Einsatz von KI setzen? Welchen Beitrag kann Open Data zur Modernisierung der Verwaltung leisten?
Offene Daten für die Verwaltungsmodernisierung
Welchen Vorteil hat Open Data für den Einsatz künstlicher Intelligenz in Behörden und für Verwaltungsmodernisierung? Darum ging es in dem Impuls, den Stefan Kaufmann, Referent für Politik und öffentlicher Sektor bei Wikimedia Deutschland und Henriette Litta, Geschäftsführerin der Open Knowledge Foundation, in die Diskussion mit den Parlamentarier*innen einbrachten.
Momentan wird bei KI-Systemen vielerorts auf generative KI gesetzt. Sie werden mit Datensätzen darauf trainiert, Texte und Bilder anhand von Aufforderungen („Prompts“) zu generieren, die anhand der Trainingsdaten wahrscheinlich wirken. Gut trainierte Large Language Models können so Texte erzeugen, die für Außenstehende häufig verblüffend natürlich wirken. Bisweilen neigen sie jedoch zu Halluzinationen – sie geben dann im Brustton der Überzeugung Sachverhalte wieder, die sich in der Realität ganz anders darstellen.
Genau das kann passieren und ist bereits passiert, wenn solche Systeme mit Bestandsdokumenten der Verwaltung gefüttert werden. Litta und Kaufmann argumentierten deswegen dafür, durch die automatisierte Veröffentlichung von Linked Open Data die Grundlage für Symbolic AI zu schaffen – also Systeme, die aus dem maschinenlesbaren Wissen der öffentlichen Hand beweisbare Schlussfolgerungen ziehen können. Die Bereitstellung von offenen und maschinenlesbaren Daten kann gewährleisten, dass staatlich eingesetzte KI-Systeme Nutzende mit zuverlässigen Informationen versorgen. So wie zum Beispiel die Wissensdatenbank Wikidata, die offene und manschinenlesbare Daten zur Verfügung stellt, die Datengrundlage für Sprachassistenzsysteme und andere Anwendungen darstellt, könnten so auch staatliche Informationen in entsprechende Auskünfte einbezogen werden.
Die Öffnung des eigenen Wissens – seien es Daten, Studien oder Gutachten – durch die Verwaltungen wird bisher oft als Maßnahme für Dritte verstanden: Durch Transparenz soll Vertrauen aufgebaut oder erhalten werden. Verwaltungsdaten sollen auch der Wirtschaft zugänglich sein und so zur Wertschöpfung beitragen.
Was dabei viel zu wenig Beachtung findet: Die technische Infrastruktur, die es dafür braucht, nutzt den Behörden selbst. Die Modernisierung der staatlichen IT-Infrastruktur, die Open Data erst möglich macht, schafft auch die Grundlagen, die für die Umsetzung des Onlinezugangsgesetzes oder auch die Registermodernisierung notwendig sind. Und ein reibungsloser Zugriff auf Informationen anderer Abteilungen im eigenen Haus vereinfacht viele Arbeiten im Behördenalltag.
Um den Einsatz von Open Data politisch zu fördern, müssen nun verschiedene Hebel in Bewegung gesetzt werden. Zentral sind neben dem Rechtsanspruch auf Open Data im Rahmen eines starken Transparenzgesetzes eine Reform des § 5 UrhG sowie die konsequente Anwendung des bereits bestehenden Servicestandards für die digitale Verwaltung. Neben diesen politischen Veränderungen braucht es jedoch auch einen allgemeinen Paradigmenwechsel, durch den der Fokus bei der Verwaltungsdigitalisierung auch auf die IT-Architektur hinter der Bildschirmvorderseite gelenkt wird. Dass dies in der Praxis funktionieren kann, zeigen Länder wie Schleswig-Holstein und Berlin. Sie begreifen Datenmanagement bereits heute als Infrastrukturaufgabe und sind im Begriff, ihre digitale Infrastruktur durch Linked Open Data auf ein solides Fundament zu stellen.
Ein finales Plädoyer des Bündnis F5 ist, dass die Zivilgesellschaft mit all ihrer Expertise stärker bei der Entwicklung und Umsetzung von Technologiestandards wie Open Data einbezogen werden muss. Durch den Wissenstransfer aus der Zivilgesellschaft kann die Verwaltung eigene Kompetenzen aufbauen und müsste viele Aspekte der strategischen Digitalisierung gar nicht neu erarbeiten. Die Abhängigkeit von externen kommerziellen Dienstleistern kann zugleich reduziert werden.
KI-Transparenzregister zur Folgenabschätzung
Wenn es um den Einsatz von KI-Anwendungen in der Verwaltung geht, ist besondere Sorgfalt geboten. Denn immerhin entscheiden Behörden täglich darüber, ob Bürger*innen staatliche Dienste und soziale Leistungen – von der Erteilung der Baugenehmigung über Rentenbezüge bis zu Sozialleistungen erhalten. Es braucht daher mindestens Transparenz und Nachvollziehbarkeit. Daher argumentierte Matthias Spielkamp, Geschäftsführer AlgorithmWatch, für ein KI-Transparenzregister. Das Register kann einen Überblick über Zweck, Hersteller, Zuverlässigkeit und Wirksamkeit der in Behörden eingesetzten KI-Anwendungen bieten. Es würde gleichzeitig dazu beitragen, die Öffentlichkeit zu informieren und Wissen zwischen Behörden auszutauschen.
Vor allem könnte das KI-Transparenzregister gewährleisten, dass die eingesetzten Anwendungen nachweisbar mit Grundrechten und demokratischen Prinzipien vereinbar sind. Zugleich würde es die KI-Kompetenz der Verwaltung erhöhen. Durch ein zweistufiges System zur Folgenabschätzung würde das Risiko negativer Folgen durch KI-Systeme minimiert. Die Ergebnisse der Abschätzung würden im Transparenzregister veröffentlicht, sodass es einen entscheidenden Beitrag dazu leisten würde, den Einsatz von KI-Systemen in Behörden besser nachvollziehen zu können. Das würde dazu führen, das Vertrauen in die Arbeit der Verwaltung zu erhalten oder sogar zu stärken. Die Behörden würden dabei von KI-Fachleuten unterstützt, sodass sie ihre Kompetenzen zugleich stärken könnten. Matthias Spielkamp appellierte deshalb an die anwesenden Politiker*innen, das KI-Transparenzregister als Teil der nationalen Umsetzung der KI-Verordnung auf den Weg zu bringen.
Auch wenn die Zeit nicht ausreichte, um die vielen offenen Fragen rund um die Themen zu besprechen, bot das parlamentarische Frühstück den Parlamentarier*innen und den Organisationen im Bündnis F5 einen wertvollen Austausch darüber, wie die Verwaltungsdigitalisierung durch Verbindlichkeiten und Vorgaben in den Bereichen Künstliche Intelligenz und Open Data und den Erfahrungsaustausch mit der Zivilgesellschaft vorangebracht werden kann.
Wie kann marginalisiertes Wissen leichter Eingang in die Wikipedia finden? Das war eine der zentralen Fragen, die auf der FemNetzCon 2024 in Hamburg diskutiert wurden. Das Netzwerktreffen der verschiedenen Wikipedianer*innen und Schreibgruppen, die sich als FemNetz für Diversität und Willkommenskultur in der Wikipedia einsetzen, fand zum vierten Mal statt.
Rund 40 Teilnehmer*innen kamen für drei Tage in den Räumen des Projekts Bildwechsel und im Freiraum des Museums Kunst und Gewerbe (MK&G) in Hamburg zusammen, um sich in Formaten wie „FemNetz-SpeedDating“, „Blick über den Tellerrand“ oder „Quo vadis, FemNetz?“ auszutauschen, untereinander noch enger zu vernetzen – und die Weichen für mehr Wissensgerechtigkeit zu stellen. „Die Stimmung war offen und produktiv“, beschreibt Wikipedianerin Helga Wiki, die das Netzwerktreffen mitorganisiert hat.
Lücken verstehen und füllen
In Arbeitsgruppen und in gemeinsamen Foren wurden nicht zuletzt auch die Gründe beleuchtet, weshalb bestimmtes Wissen in der Wikipedia ganz oder in einzelnen Artikeln fehlt. „Teilweise hat das historische Ursachen“, sagt Helga Wiki: „Beispielsweise waren queere Lebensweisen lange kriminalisiert und besaßen entsprechend keine gesellschaftliche Sichtbarkeit.“ Gerade vor diesem Hintergrund sollte die Wikipedia stets auch neues Wissen in bestehende Artikel aufnehmen, betont die Wikipedianerin. Sie nennt als Beispiel eine jüngst erschienenen arte-Dokumentation über den Musiker Little Richard, die erstmals dessen lange verschwiegene Homosexualität thematisierte – ein Aspekt, der im „ansonsten sehr guten und differenzierten Wikipedia-Eintrag“ über den Künstler entsprechend noch fehle.
Überhaupt findet Helga Wiki, dass die Community stets „den jüngsten Stand der Diskussionen“ abbilden sollte: „Im Zusammenhang mit Transidentität von historischen Personen wird beispielsweise oft noch fälschlich das Schlagwort ‘Travestie’ verwendet.“
Error: Unsupported or missing media
Was ist relevant für die Wikipedia?
Im Zusammenhang mit marginalisiertem Wissen wurde auf der FemNetzCon auch über die Relevanzkriterien der Wikipedia diskutiert. Diese von der Community ausgearbeiteten Kriterien legen fest, was in der Online-Enzyklopädie Platz findet und was nicht. Eine Arbeitsgruppe verhandelte dazu in Hamburg einige Leitfragen. Darunter zum Beispiel: Werden die bestehenden Relevanzkriterien auf alle Geschlechter gleichermaßen angewendet? Oder: Wie können die Kriterien verändert werden, um Frauenleistungen umfassender abzubilden?
Wikipedianerin ScheWo, die Teil der Arbeitsgruppe war, hält fest: Die Relevanzkriterien seien zwar grundsätzlich neutral, alledings zeige sich aufgrund der jahrhundertelangen Diskriminierung von Frauen, „dass deren Leistungen durch die bestehenden Relevanzkriterien weniger anerkannt werden.“
Wikipedianerin Alpenhexe nennt als Beispiel die „Liste bedeutender Bergsteiger“ in der Wikipedia. Dort sei unter anderem behauptet worden, dass es keine bedeutenden Bergsteigerinnen gebe. Alpenhexe hat das korrigiert. Den Umstand, dass weibliche Leistungen in der Wikipedia vielfach ausgeblendet würden, beschreibt sie als ihre Hauptmotivation, überhaupt als ehrenamtliche Autorin mitzumachen.
Queeres Wissen, Wissen queeren
Wissen ist nicht nur Macht – Wissen bildet immer auch Machtverhältnisse ab. So wiederum beschreibt Helga Wiki eine der zentralen Erkenntnisse aus der Veranstaltung „Queere KI und Wikipedia“, die am Vorabend der FemNetzCon ebenfalls in Hamburg stattfand. Mit dabei waren die Kultur- und Medientheoretiker*innen Sara Morais dos Santos Bruss und Lotte Warnsholdt. Diskutiert wurde darüber, wie verhindert werden kann, dass KI-Systeme, die auch mit den Datensätzen der Wikipedia trainiert werden, Gender-Stereotype reproduzieren, die in diesen Daten enthalten sind.
KI, so Helga Wiki, „ist nie ahistorisch oder neutral, sondern eingebettet in die Machtverhältnisse unserer Gesellschaft.“ Wissen zu „queeren“ bedeute entsprechend, genau diese Herrschaftsgefälle kritisch zu durchleuchten. Was auch für die Bestände vieler Archive oder Museen gelte, die oftmals auf gewalttätige koloniale Sammlungspraxen zurückgingen – und nicht unhinterfragt bleiben dürften.
Last but not least wurde auf der FemNetzCon auch darüber debattiert, wohin sich das Netzwerk in Zukunft entwickeln soll, um wirksam zu bleiben. Das Schlagwort: „Quo vadis, FemNetz?“. Die Teilnehmer*innen überlegten, ob FemNetz eine neue Organisationsform für den geschlossenen Auftritt braucht – etwa als User Group, wie es viele im Wikiversum gibt.
Dafür fand sich allerdings keine Mehrheit: „FemNetz möchte offen bleiben“, fasst Helga Wiki das Ergebnis dieser Diskussion zusammen. „Wir wollen unsere fluide Struktur beibehalten und weiterhin neue Impulse von Individuen und Gruppen aufnehmen – kurz gefasst: FemNetz soll lebendig bleiben!“
FemNetz ist ein Netzwerk von unterschiedlichen Wikipedianer*innen und Schreibgruppen mit feministischen Anliegen. FemNetz möchte den Anteil der schreibenden und repräsentierten Frauen sowie von inter, trans und nonbinären Personen auf Wikipedia nachhaltig erhöhen. Aktive Gruppen des Netzwerks sind: WomenEdit, Who writes his_tory? mit Verbindung zu Art+Feminism, wiki:wo:men und weitere Gruppierungen sowie einzelne engagierte Autor*innen vorwiegend aus Deutschland, Österreich und der Schweiz (D-A-CH).
Für Einsteiger*innen, die gern bei Wikipedia mitmachen würden, aber nicht genau wissen, wie das funktioniert, gibt es das FemSupport-Netzwerk – die Ansprechpartner*innen leisten hier gern Hilfe.
An jedem 4. Montag im Monat von 19 bis 20 Uhr veranstaltet FemNetz den Online-Workshop 60 Minuten zu Gender & Diversity in der Wikipedia. Auch hier sind Einsteiger*innen willkommen!
Diese weiteren Initiativen und Projekte machen sich ebenfalls für mehr Sichtbarkeit von Frauen in der Wikipedia stark – und zwar ganzjährig:
WomenEdit
Bei regelmäßigen Treffen von Wikipedianerinnen wird gemeinsam editiert – vor Ort und online. In Berlin jeweils am ersten Mittwoch im Monat in der Geschäftsstelle von Wikimedia Deutschland und am dritten Mittwoch im Lokalen Wikipedia-Raum WikiBär. In Erlangen trifft sich WomenEdit üblicherweise am zweiten Montag im Monat in der Stadtbibliothek.
Women in Red
Der deutschsprachige Teil des internationalen kollaborativen Projekts „Women in Red“ hat zum Ziel, so viele rote Links auf fehlende Frauenbiografien in der Wikipedia wie möglich in blaue umzuwandeln.
wiki:wo:men
Der Arbeitskreis wiki:wo:men trifft sich monatlich in Stuttgart. Eingeladen sind alle Menschen, die Interesse am Thema „Frauen in der Wikipedia“ haben – egal, ob Wikipedianer*innen oder Neulinge. Die Treffen finden in der Regel an jedem 3. Freitag im Monat statt.
Workshop-Reihe 60 Minuten – Gender & Diversity in der Wikipedia
Die Online-Workshop-Reihe dient dem länderübergreifenden Austausch (Deutschland, Österreich, Schweiz) zu Fragen rund um Gender und Diversity in der Wikipedia – an jedem 4. Montag im Monat von 19 bis 20 Uhr.
Mentorinnennetzwerk FemSupport
Das feministische Support-Netzwerk bietet kollegiale Unterstützung für Frauen, die bei Wikipedia aktiv werden wollen, sich aber im Dschungel der Hilfeseiten und Video-Tutorials (noch) nicht zurechtfinden.
Berlinale FilmFrauen Edit-a-thon
Der Edit-a-thon findet jährlich am ersten Berlinale-Wochenende in Berlin statt und bringt mehr Biografien über Filmfrauen aller Sparten in die Wikipedia: von der Regisseurin bis zur Tonmeisterin. Hier gibts einen lesenswerten Rückblick auf den Berlinale Edit-a-thon 2024.
Wiki Riot Squad Berlin
Im Rahmen von Schreibwerkstätten und Edit-a-thons werden beim Projekt Wiki Riot Squad Wikipedia-Artikel diskutiert und bearbeitet – der Fokus liegt dabei auf möglichen Gender Bias, also einer verzerrten Wahrnehmung durch sexistische Vorurteile und Stereotype.
Art+Feminism
Diese Gemeinschaft von Aktivist*innen setzt sich dafür ein, Informationslücken im Zusammenhang mit Geschlecht, Feminismus und Kunst zu schließen, beginnend mit Wikipedia.
Who writes his_tory?
Dieses Schweizer Projekt hinterfragt die Reproduktion von Wissen und struktureller Diskriminierung im Internet und vor allem auf Wikipedia. In der Schweiz sind außerdem Les sans pagEs (französischsprachig) und die Künstler*innengruppe Femme Artist Table FATart aktiv.
Zwischen dem 1. Januar und dem 5. März 2024 nahm ich an einer Mission des italienischen Nationalen Antarktis-Forschungsprogramms (PNRA) an Bord des Eisbrechers RV Laura Bassi teil, die durch das Rossmeer, das größte Schutzgebiet der Welt, führte. Da ich mich in meiner Forschung als analytischer Chemiker an der Universität Genua mit Umwelt und Klimawandel beschäftige, war es nicht das erste Mal, dass ich die Antarktis bereiste. Aber dieses Mal hatte die Mission einen besonderen Mehrwert, der mit einer anderen großen Leidenschaft von mir zusammenhing: Wikipedia.
Bei meinen vier vorherigen Missionen hatte ich bereits mit Kolleg*innen, die ich auf dem Schiff oder in der Forschungsbasis traf, über meine ehrenamtliche Arbeit an Wikipedia gesprochen und dabei oft andere Wikipedianer*innen oder Menschen kennengelernt, die sich sehr für das Projekt interessierten. Gleichzeitig wusste ich – wie viele andere Leser*innen oder Freiwillige –, dass sowohl in der italienischen Wikipedia, als auch in anderen Sprachversionen Artikel fehlen oder nur unvollständig vorhanden sind, die sich mit der Antarktis und ganz allgemein mit dem Klimawandel befassen. Vor meiner Abreise hatte ich also die Idee, einen Edit-a-thon, einen Wikipedia-Schreibmarathon, zu organisieren, der sich genau diesen Themen widmet. Glücklicherweise wurde mein Vorschlag vom Chef der Mission und anderen Kolleg*innen positiv aufgenommen. Und so organisierten wir den ersten Edit-a-thon aus der Antarktis.
Technische Grenzen
Wie man sich vorstellen kann, ist das Leben auf einer antarktischen Station nicht einfach, vor allem, wenn sie sich auf einem Schiff befindet, das sich durch das Eis bewegt, gegen den Widerstand von starken Winden und manchmal erheblichen Wellen. Alle an der Mission beteiligten Personen müssen Experimente im Zusammenhang mit ihrem Forschungsprojekt durchführen, außerdem können sie von Kolleg*innen zu Hilfe gerufen oder gebeten werden, Messungen, Probenahmen oder andere Experimente für Wissenschaftler*innen durchzuführen, die sich nicht auf der Station befinden. Der Arbeitsplan ist in variablen Schichten über 24 Stunden verteilt, so dass alle Labore mit maximaler Effizienz genutzt werden können.
Das größte Hindernis für uns Wikipedianer*innen war jedoch ein anderes: Ende Januar 2024, als wir uns entschieden, den Edit-a-thon zu starten, war der Internetzugang begrenzt. Abgesehen von den Rechnern, die von den Navigations- und Logistikdiensten verwendet wurden, hatten nur drei Computer Zugang zu einer Verbindung. Was die Arbeit deutlich erschwert, wenn man in der Wikipedia editieren will. Dieses Problem konnte jedoch ganz einfach gelöst werden: Wir haben offline gearbeitet und uns mit Wikimedia Italien abgestimmt, um Artikel gleich zu Beginn des Marathons zu bearbeiten und zu veröffentlichen. Zusammen mit unseren Kollegen Paola Rivaro, Angela Garzia, Craig Stevens, Jasmin McInerney und Liv Cornelissen schrieben wir also die ersten Artikel für den Edit-a-thon, die als Startschuss für Freiwillige dienten, die aus Italien teilnehmen wollten.
Die Ergebnisse
Wobei der Zeitraum unserer Aktion weit über einen normalen Edit-a-thon hinausging. Ursprünglich hatten wir der italienischen Wikipedia-Community vorgeschlagen, an einer Beitragswoche zum Thema Antarktis und Klimawandel teilzunehmen. Der Vorschlag wurde sehr gut aufgenommen, weit besser noch als erwartet: Aus der Woche, die am 1. Februar 2024 begann, wurde erst ein Monat – und dann entstand daraus ein eigenständiges neues Projekt in der italienischen Wikipedia, das sich ganz der Antarktis widmet, mit einer Antarktis-Basis als Plattform für Diskussionen. Ich hätte nie mit einem solchen Enthusiasmus gerechnet, sowohl bei meinen Schiffskameraden, als auch bei den Freiwilligen der Wikipedia.
Die Teilnahme ausländischer Kolleg*innen, die zur englischen Wikipedia beigetragen haben, war eine unerwartete und sehr willkommene Überraschung (sogar mit Themenfotos, die von Liv Cornelissen und Luisa Fontanot aufgenommen und hochgeladen wurden!). Ich denke, dass alle Forschenden an Bord verstanden haben, wie wichtig die Verbreitung wissenschaftlicher Erkenntnisse gerade auch über eine Plattform wie Wikipedia ist, die Freies Wissen und wichtigen Entdeckungen einem möglichst breiten Publikum zugänglich macht. Wenn wir als „Expert*innen auf unserem Gebiet“ dafür sorgen, dass die Informationen, die die Leser*innen online finden können, zuverlässig sind, ist der Nutzen für alle offensichtlich.
Abschließend möchte ich auch den Verantwortlichen des italienischen Nationalen Antarktis-Forschungsprogramms (PNRA) und Wikimedia Italien für ihr Interesse und ihre Unterstützung in Sachen Logistik und Kommunikation danken, die für den Erfolg unserer Initiative von grundlegender Bedeutung war.
Francisco Ardini ist außerordentlicher Professor für analytische Chemie an der Universität von Genua. Er erforscht die Kontamination in polaren Umgebungen, nimmt an Projekten und Expeditionen in der Arktis und Antarktis teil und führt Aufklärungsaktionen zu diesem Thema für Schulen und Kulturvereine durch. Seit 2020 initiiert er Aktivitäten zu Wikimedia-Projekten (Wikibooks, Wikipedia, Wikivoyage, Wikimedia Commons) für Schulen, Universitäten und Museen im Bereich Chemie und Klimawandel.
Bisher lief das so: Die Wikimedia Foundation in den USA ist die größte und erste Wikimedia-Organisation. Sie ist Betreiberin der Wikimedia-Projekte und die Zentrale der Wikimedia-Organisationen und -Gruppen, die sich auf der ganzen Welt aufgrund ihrer Begeisterung für Freies Wissen gebildet haben. Die Foundation hat bislang stets die globalen Entscheidungen getroffen, allerdings wurden damit nicht immer die Bedürfnisse der Wikimedia-Länderorganisationen berücksichtigt. Damit diese Entscheidungen zukünftig gerechter und nachhaltiger getroffen werden, wird nun auf die Entwicklung dezentraler Governance-Strukturen gesetzt. Nicole Ebber ist Leiterin des Teams Governance und Movement Relations bei Wikimedia Deutschland und erzählt uns mehr über die Bedeutung dieser Entwicklung – für das Movement und die Welt des Freien Wissens.
Hallo, Nicole! Wie kam es zu dem Gedanken, sich innerhalb des Wikimedia Movements anders aufzustellen bzw. gerechter zu organisieren?
Der Gedanke entstand bereits 2013, 2014, als Wikimedia Deutschland das Projekt “Chapters Dialogue” durchgeführt hat, in dem wir uns mit allen Wikimedia-Mitgliederorganisationen weltweit ausgetauscht haben. Da stand bereits die Frage im Raum, wie wir bessere Entscheidungen im Sinne jener treffen, die sie am meisten betreffen oder wie Ressourcen sinnvoller verteilt werden können. Ende 2016 startete dann offiziell ein großangelegter Strategieprozess unter der damaligen Geschäftsführerin der Wikimedia Foundation, Katherine Maher. Ein Ziel war auch, in die Zukunft von Wikimedia über Wikipedia hinauszublicken. Die Bewegung sollte sich intern stärken, um gemeinsam eine kraftvolle Zukunft für Freies Wissen zu gestalten. Ein Ergebnis dieses Prozesses von 2018 bis 2020 waren 10 Handlungsempfehlungen – eine davon: Gerechtigkeit in der Entscheidungsfindung. Damit sollen Beschlüsse nicht nur zentral bei der Wikimedia Foundation liegen, sondern auch dezentralisiert und repräsentativer werden.
Welche Vorteile bringt ein dezentraler Ansatz in der Bewegung und warum kann das für jede Organisation ein guter Weg sein?
Es ist wichtig, diejenigen einzubeziehen, die von Entscheidungen betroffen sind, um ihre Unterstützung zu gewinnen. Und dadurch, dass unser weltweites Movement so groß und divers ist und sich aus vielen Teilen der Welt zusammensetzt, ist es besonders wichtig. Ein Beispiel, das verdeutlicht, wie eine zentrale Entscheidung schiefgehen kann, war der Branding-Prozess der Wikimedia Foundation vor einigen Jahren. Die Foundation beschloss, sich in “Wikipedia Foundation” umzubenennen. Dies führte zu starken Protesten innerhalb der Community. Letztendlich musste die Entscheidung zurückgenommen oder zumindest auf Eis gelegt werden, nachdem bereits viel Geld investiert worden war. Eine frühere Einbindung der Community und eine dezentrale Entscheidungsstruktur hätten wahrscheinlich dazu beigetragen, sowohl finanzielle als auch emotionale Belastungen zu vermeiden. Ich denke, eine größere und frühe Beteiligung in Entscheidungsprozessen fördert ein stärkeres Engagement und Verantwortungsbewusstsein für jede Form von Organisation.
Vom 19. bis 21. April fand in Berlin der Wikimedia Summit statt. Mit dabei waren 170 Wikimedianer*innen aus über 60 Ländern. Was macht dieses Zusammentreffen so besonders für das Movement?
Der Wikimedia Summit ist der Ort, an dem sich einmal im Jahr Vertreter*innen der Affiliates, also der Länderorganisationen und anderer Zusammenschlüsse wie die Wikimedia User Groups treffen, um gemeinsam an der Zukunft der Bewegung zu arbeiten. Die Veranstaltung ist jedoch kein klassisches Konferenzformat, wo Leute vorher Vorträge einreichen und im Anschluss auf der Bühne stehen. Es handelt sich um ein wirkliches Arbeitstreffen, bei dem alle Teilnehmer*innen drei Tage lang aktiv mitmachen. Vor der Veranstaltung gibt es u. a. Vorbereitungsmeetings und Materialien zum Lesen. Beim Summit selber teilen sich dann die Teilnehmer*innen in Arbeitsgruppen auf, die in interaktiven Formaten Vorschläge zur zukünftigen Zusammenarbeit erarbeiten. Die Arbeitsgruppen kommen im Laufe des Wochenendes regelmäßig zusammen, präsentieren ihre Fortschritte, geben Feedback zu den Ergebnissen und arbeiten dann daran weiter, sodass sie am Ende gemeinsame Resultate schaffen.
Im Mittelpunkt stand auf dem Summit die gemeinsame Arbeit an der sogenannten Movement Charta. Um was für ein Dokument handelt es sich dabei?
Die Charta ist ein grundlegendes Dokument für die Zukunft unseres Movements, das von einem Komitee aus Ehrenamtlichen und Mitarbeitenden der Wikimedia-Organisationen erarbeitet wird. Sie definiert das Rahmenwerk, die Werte, Prinzipien und Kriterien für Entscheidungen und Prozesse im Movement. Ein zentraler Aspekt ist die Etablierung eines Global Council, einem globalen Rat, der Entscheidungen treffen und das Movement mit all den Ehrenamtlichen und Wikimedianer*innen repräsentieren soll. Die Charta legt auch fest, dass Entscheidungen, die nicht global getroffen werden müssen, auf lokale oder regionale Ebenen übertragen werden können.
Welches waren zum Ende der Veranstaltung die wichtigsten erarbeiteten Inhalte bzw. Entwicklungen zur Charta?
Wir haben auf dem Wikimedia Summit mit 170 Teilnehmer*innen und drei Tagen langer intensiver Arbeit tatsächlich handfeste Ergebnisse erzielt, sodass man auch sieht, wow, die Mühe hat sich gelohnt! Es wurde eine beeindruckende Einigkeit erzielt, die sich in 46 breit unterstützten Charta-Statements widerspiegelt. Das Movement Charter Drafting Committee wird diese Statements sowie das Feedback aus den nicht-anwesenden Communitys prüfen und teilweise in die finale Version der Charta einfließen lassen. Zusätzlich zur Charta-Erstellung ist auf dem Summit auch die Gründung einer Gruppe gelungen, die ein neues Konzept für zukünftige Treffen der Wikimedia-Organisationen entwickeln wird. Wir haben viele Jahre lang als Wikimedia Deutschland den Summit ausgerichtet und wollen diese Verantwortung weitergeben, damit die Diversität des Movements besser repräsentiert wird.
Was motiviert euch zu diesem Schritt?
Da wir in unserer Movement-Strategie Prinzipien wie Zugang, Partizipation und Gerechtigkeit verankert haben, passt die Veranstaltung, wie sie bisher durchgeführt wurde, nicht mehr dazu. Bislang wurden Entscheidungen über Themen, Zahl der Teilnehmer*innen, Programmgestaltung und Outputs letztendlich von Wikimedia Deutschland und in Absprache mit der Wikimedia Foundation getroffen, ohne ausreichende Beteiligung der anderen Affiliates oder Community. Wenn wir unsere Entscheidungsstrukturen gleichberechtigter gestalten wollen, gehört die Ausrichtung und Planung von Arbeitstreffen konsequenterweise auch dazu.
Inwieweit haben die Aktivitäten des Wikimedia Movements eine Auswirkung auf die Wissensgerechtigkeit weltweit?
Unsere Vision ist ein globales Wissen, das nicht von Machtstrukturen und Privilegien geprägt ist, sondern von einer breiten Palette an Stimmen und Erfahrungen. Wenn wir es schaffen, ein gerechteres Movement aufzubauen, können wir nicht nur bisher marginalisierte Communitys stärken, sondern auch unsere eigene Offenheit und Vielfalt erweitern. Diese Veränderungen sind nicht nur für das Movement wichtig, sondern haben das Potenzial, die gesamte Welt zu bereichern und zu verbessern.
Das Museum für Naturkunde in Berlin verfügt über eine gigantische Sammlung. Schätzungsweise umfasst sie rund 30 Millionen Objekte, genau gezählt wurde das nie. Was auch bedeutet: Es liegen noch Berge an Informationen in den Beständen der Kulturinstitution, die darauf warten, erschlossen zu werden. Genau daran arbeitet das Museum im Rahmen eines ambitionierten Zukunftsplans.
Eine Säule dieses von Bund und Land geförderten Vorhabens ist die Sammlungserschließung und -entwicklung. „Dabei geht es eben nicht nur darum, Bilder von Objekten digital verfügbar zu machen“, erklärt Sabine von Mering, biologische Datenwissenschaftlerin im Forschungsbereich „Zukunft der Sammlung des MfN. Vielmehr sei das Ziel „eine offene Forschungsinfrastruktur zu schaffen, die allen Interessierten zugänglich ist“. Um dies zu erreichen, nutzt von Mering zusammen mit Kolleg*innen die Potenziale von Linked Open Data. „Wir müssen die institutionellen Datensilos aufbrechen, die Daten frei verfügbar machen und international zusammenarbeiten“, ist die studierte Botanikerin überzeugt: „Dann sind viele spannende Analysen zu Netzwerken möglich“.
Ein Sammler*innen-Projekt als Ausgangspunkt
Am Museum für Naturkunde Berlin hat von Mering dazu ein Sammler*innen-Projekt ins Leben gerufen. Grundlage dieses Forschungsunternehmens – das aus dem hauseigenen Innovationsfonds gefördert wurde – ist ein internes Wiki des MfN, das Informationen zu rund 600 historischen Sammler*innen mit Bezug zur enthält: Wissenschaftler*innen, Präparator*innen, Illustrator*innen. „Personen“, erklärt von Mering, „sind die zentrale Einheit im Wissensnetz und als Anknüpfungspunkt hoch relevant.“ An sie ließen sich andere Entitäten andocken: Objekte in Sammlungen, Publikationen, Archivalien, Fotos – und natürlich andere Personen. „Diese Vernetzung war unser ursprüngliches Interesse“, so die Wissenschaftlerin.
Als Pilotdatensatz wurde das interne Sammlerwiki im Rahmen eines Edit-a-thons im September 2022 noch per Hand in Wikidata übertragen. „Wikidata ist mehrsprachig, maschinen- und menschenlesbar und kollaborativ – und deswegen ein sehr nützliches Tool für unsere Arbeit“, betont von Mering. Dadurch, dass den Personen nach dem Prinzip der Linked Open Data ein eindeutiger Identifikator zugeordnet wird, lassen sich die Verknüpfungen herstellen, die für die Forschung spannend sind.
Zunächst einmal gilt das für die Sammlung des Museums selbst, die auch Archiv und Bibliothek mit einbezieht: War Person X vielleicht nicht nur Ornitholog*in, sondern hat daneben auch Insekten gesammelt und Bücher geschrieben? Aber möglich wird durch LOD vor allem auch „der Blick über den Tellerrand“, wie Sabine von Mering beschreibt – eine Domänen-übergreifende Verknüpfung: „Beispielsweise hat Person X auf Reisen auch ethnologische Objekte gesammelt, die sich im Ethnologischen Museum Berlin befinden. Oder die Person hat neben Insekten auch die Wirtspflanzen der Tiere gesammelt, die im Herbarium des Botanischen Gartens liegen – um nur die möglichen Berlin-Bezüge zu veranschaulichen.“ Denn natürlich lassen sich mit Linked Open Data solche Verknüpfungen weltweit herstellen.
Mehr Sichtbarkeit für Hidden Champions
Für die Forschung bedeutet das einen enormen Gewinn. „Wenn wir Sammlungsdaten inklusive Daten zu Personen mit Sammlungsbezug zugänglich und nachnutzbar machen“ – den FAIR Data-Prinizipien folgend –, „helfen sie uns als globale Wissensressource und offene Forschungsinfrastruktur für alle dabei, viele offene Fragen zu beantworten“, von Mering. Fragen etwa aus dem Themenspektrum Biodiversitätsverlust, oder zu unterrepräsentierten Gruppen, sogenannten „hidden champions“ – was etwa lokale Guides, Sammler*innen oder Informant*innen sein können, aber auch Frauen, die einen wichtigen Beitrag zur Forschung geleistet haben, deren Verdienste jedoch Männern zugeschlagen wurden. Kurzum: Es geht zentral auch darum, die Sichtbarkeit und Auffindbarkeit dieser „versteckten“, sprich: marginalisierten Menschen zu erhöhen.
Gefunden im Sammlerwiki: Eine dieser Hidden Champions ist die Zoologin Bat-Sheva Aharoni, Q108309256, (im Bild mit ihrem Vater Israel Aharoni) promovierte 1932 über die Muridae (kleine Nagetiere) Palästinas an der Friedrich-Wilhelms-Universität Berlin (heute Humboldt-Universität). Das Foto zeigt sie in den Gängen der zoologischen Sammlung der Hebräischen Universität Jerusalem. Aufgenommen wurde das Foto vor 1947. Den Wikidata-Eintrag zu der Zoologin hat Sabine von Mering angelegt.
Von den rund 600 Personen im internen Sammler-Wiki des Museums für Naturkunde Berlin waren zum Beispiel nur 11 Frauen. Sabine von Mering und ihr Team wissen, dass hier ein Bias vorliegt und es tatsächlich viel mehr gewesen sein müssen, die einen Beitrag geleistet haben. Entsprechend suchen die Wissenschaftler*innen in der Folge des Sammler*innen-Projektes nun weitere Frauen mit Bezug zum MfN. Das Problem: Über sie ist oft so wenig bekannt, dass jede Recherche ein kleines Forschungsprojekt für sich bedeutet.
Zusammen mit der neuseeländischen Wissenschaftlerin und Wikimedian Siobhan Leachman – die auf der Wikimania 2023 als „Wikimedia Laureate“ ausgezeichnet wurde – hat von Mering zudem ein Data-Paper zu Pflanzengattungen erstellt, die nach Frauen benannt wurden. Innerhalb der Gattungen, die überhaupt den Namen von Personen tragen, machen sie wiederum nur einen Bruchteil aus, ca. 700 haben die beiden zusammengetragen, bei Männern ist es ein Zehnfaches. Ihr Datensatz, der auch über Wikidata verfügbar ist, hilft wiederum, Verknüpfungen herzustellen – zwischen der Pflanzengattung und der Namensgeberin, die vielleicht Botanikerin war, Schriftstellerin oder eine Mäzenin, die wissenschaftliche Arbeit unterstützt hat. Auch hier ist das Anliegen, die Sichtbarkeit zu erhöhen.
Arbeit an kolonialen Kontexten
Linked Open Data spielen am Museum für Naturkunde Berlin zudem dort eine wichtige Rolle, wo es um die historische Kontextualisierung und die Reflektion von Wissen im Zusammenhang mit Kolonialgeschichte geht. Am Haus existiert ein „Center for the Humanities of Nature“. Eine Gruppe von Historiker*innen, Sozial-Anthropolog*innen oder auch Kulturwissenschaftler*innen durchleuchtet die eigenen Bestände und liefert Daten, die zur Aufarbeitung von Unrechtskontexten und Sammelpraktiken beitragen, die oft mit dem Begriff „Raub“ präziser beschrieben sind. Provenienzforschung, wie sie das MfN betreibt, bedeutet immer auch das Ausloten von Grauzonen. „Viele Wissenschaftlerinnen und Wissenschaftler haben vielleicht nicht selbst geraubt, aber auch koloniale Strukturen genutzt – das ist ein Erkenntnis- und ein Lernprozess“, so Sabine von Mering.
Wie sich solche Verflechtungen auch in Wikidata abbilden lassen, ist eine Frage, an der sie gegenwärtig unter anderem mit Lucy Patterson – Projektmanagerin digitales Kulturgut bei Wikimedia Deutschland e.V. – sowie dem Wissenschaftler Yann LeGall forscht, der an der Technischen Universität Berlin in das Projekt „The Restitution of Knowledge“ involiviert ist. Die Überlegung ist: „Wie kontextualisiere ich, dass der Kolonialbeamte aus Deutschland auch ein Plünderer war?“. Oder: Wie lässt sich in strukturierten Daten der Unterschied zwischen einer „klassischen“ Forschungsexpedition und einer Strafexpedition („punitive expedition“) sichtbar machen – Gewaltunternehmungen von Kolonialtruppen, in deren Zuge nicht selten auch „gesammelt“ wurde?
Hans Dominik (rechts), Q879441, war ein Kolonialoffizier der Schutztruppe, der als dienstältester Offizier in der Kolonie Kamerun ein brutales und mörderisches Erbe hinterließ. Im Sammlerwiki wird auch angegeben, dass er (wahrscheinlich geplünderte) Gegenstände in die Sammlungen des Linden-Museums und des Ethnologischen Museums Berlin eingebracht hat. Zu sehen ist er auf dem Foto in Kamerun, im Hintergrund ist der Bismarck Brunnen in Buea zu sehen.
Mit kolonialen Fragen hat sich auch ein zweiter – diesmal öffentlicher – Edit-a-thon am MfN beschäftigt, bei dem Menschen aus neun Ländern gemeinsam Wikidata-Einträge zu Personen editiert haben, die in der früheren deutschen Kolonie Kamerun tätig waren. Mit dabei waren auch Teilnehmer*innen von verschiedene Wikimedia-Usergroups, etwa aus Nigeria und Kamerun. „Wichtig ist“, betont Sabine von Mering, „bei solchen Projekten nicht die koloniale Perspektive zu replizieren und sich nur auf die bekannten weißen Akteure zu fokussieren“. Das Ziel sei vielmehr, Daten verfügbar zu machen, die gerade auch für die Menschen aus Herkunfts-Communities einen Wert hätten, „um beispielsweise Informationen über ihre Vorfahren zu gewinnen oder über die Vorgänge in ihrem Land zur Kolonialzeit.“
Während des Edit-a-thons wurden in Wikidata aber auch Items zu heute in Kamerun tätigen Botaniker*innen, Biolog*innen oder Zoolog*innen erstellt – wobei sich allerdings ein Bias gezeigt hat, der vielen Datenbanken gemein ist: „Sowohl für Frauennamen weltweit als auch für Namen aus dem Globalen Süden existieren oft keine Datenobjekte“, sagt von Mering. „Englische oder französische Namen sind als Items selbstverständliche vorhanden, aber ein weiblicher Vorname aus Nepal nicht.“ Umso wichtiger sei es, gerechte Wege zu finden, um mehr Communities auch aus nicht-westlichen Ländern in die gemeinsame Arbeit an Wikidata einzubinden.
Schnittstellen zwischen Wikimedianer*innen und Institutionen
In der Forschungs-Community sei die freie Datenbank derweil immer akzeptierter als „zentraler Ort für die Verknüpfung von Informationen“, beobachtet die Datenwissenschaftlerin. Sie selbst hat im Zuge des Sammler*innen-Projektes erfolgreich eine neue Wikidata-Property beantragt, die Person und Institution verknüpft: “collection items at”. Damit lässt sich nun die Information weitergeben, dass von Person X Objekte nicht nur im MfN, sondern beispielsweise auch im Ethnologischen Museum Berlin vorhanden sind.
Generell sieht Sabine von Mering noch viel Potenzial für die Nutzung von Linked Open Data in Kulturerbe-Institutionen. Wobei daran natürlich stets die Frage von Ressourcen hinge. Auf technischer Ebene sei viel Arbeit bei der Erschließung von Daten nötig, „bei den vielen Schritten, die Informationen in Datenbanken einzupflegen und zu prüfen.“ Eine vertrauensvolle Ressource zu sein, sei gerade in Zeiten von Fake News das Wichtigste für eine Forschungseinrichtung. Genauso aber gelte es, im Kontext von Linked Open Data Fragen nach Wissensgerechtigkeit in den Blick zu nehmen, sich global auszutauschen, Schnittstellen zwischen Wikimedians, Forschenden und Institutionen weltweit zu schaffen. „Letztlich können wir unsere 30 Millionen Objekte nicht allein erschließen“, bilanziert Sabine von Mering. „Es ist sinnvoll, die globale Community mit einzubinden.“
The overarching question when it comes to the topic of data-collection is always: What is the right balance between collection and protection of data? The crucial factor here clearly is the intention: Is data collected to uncover or observe discrimination? Then it should be collected. But if you start to collect data about a massive group of people in their most vulnerable situation – and without purpose: Don’t do it. As so often, the emphasis lies within the context.
The collection of data: How data about who we are influences our lives
Rahman referred with this comment to the UN Refugee Agency’s database which holds a massive amount of biometric data, from refugees and displaced persons. These are oftentimes collected with no justifiable reason and without the knowledge of the persons concerned. She affirmed: there is no need for a standing, ever growing database. She demanded to only collect data in a privacy respecting way with full consent of the people affected and with a clearly stated social purpose, e.g. examination of structural discrimination.
Categorization of data in the digital age
Data nearly always is categorized. Consequently, data concerning human beings as well. With digitalisation, the habit of categorizing per se may have not become particularly worse, as European colonizers started categorizing people long before digitalisation. But one could say that the matter now is maybe more fixed and more extensive: with one click, you can share every categorized data you collected and thus influence people’s lives in a decisive way.
Videoaufzeichnung der Diskussion (Englisch)
By playing the video you agree that YouTube and Google might store and process your data. Please refer to Google’s Privacy Policy.
Discriminatory aspects of data collections
Digital data is assigned to different people differently without them even knowing, stated Rahman. She pointed to a very specific example regarding this topic: the so-called Gangs Matrix in the UK. This database collected data from young, mostly black men in the UK based on the unjustified suspicion they might be members of a gang. This highly discriminatory database influenced people’s everyday lives negatively. For example, they were denied jobs because they were registered or schools did not accept the children of those affected. The justification for the collection of their data was in turn rooted in racist prejudices.
Here lies the problem with collecting biometric data: it is often deeply connected with various factors, such as a passport, skin color or even a refugee status.
The entire book presentation and subsequent discussion can be rewatched in this video
Zara Rahmans „Machine Readable Me“: Wann Daten sammeln Schaden anrichtet
In welchen Datenbanken hinterlassen wir Spuren – mit oder ohne unser Wissen? Wie werden diese Daten genutzt, um Individuen und Gruppen zu kategorisieren und zu bewerten? Und welche – mitunter diskriminierenden – Auswirkungen haben diese Bewertungen? Um diese Fragen ging es bei der Präsentation von Zara Rahmans Buch “Machine Readable Me”. In der Diskussion mit Aline Blankertz zeigte die Autorin auf, wie mit Daten, die über Individuen gesammelte werden Macht ausgeübt wird – weil sie zur Überwachung genutzt werden oder bestimmen, ob wir staatliche oder private Dienstleistungen erhalten.
Wie Datensammlungen unser Leben beeinflussen
Die übergreifende Frage beim Thema Datensammlung ist immer: Was ist die richtige Balance zwischen Sammeln von Daten und Schutz von Daten? Entscheidend ist dabei immer die Intention: Daten sammeln, um Diskriminierung aufzudecken und zu beobachten? Ja, natürlich! Aber eine ziellose Sammlung von Daten einer großen Menschengruppe in einer extrem verletzlichen Situation? Nein. Wie so oft liegt die Betonung auf dem Kontext.
Rahman verwies mit dieser Bemerkung auf die Datenbank der UN Refugee Agency, die eine riesige Menge biometrischer Daten hauptsächlich von geflüchteten Personen enthält, und die ohne rechtfertigenden Grund gesammelt werden. Sie betont: Es besteht keine Notwendigkeit für eine solche ständig wachsende Datenbank. Rahman forderte, Daten nur unter Wahrung der Privatsphäre und mit der vollen Zustimmung der Betroffenen zu erheben und einen klar formulierten sozialen Zweck zu verfolgen, z. B. die Untersuchung von struktureller Diskriminierung.
Kategorisierung von Daten im digitalen Zeitalter
Daten werden fast immer kategorisiert. Folglich auch Daten, die Menschen betreffen. Mit der Digitalisierung hat sich die Gewohnheit des Kategorisierens vielleicht nicht neu erfunden, da europäische Kolonisatoren schon lange vor der Digitalisierung damit begonnen haben, Menschen zu kategorisieren. Aber man könnte sagen, dass die Verbreitung der Daten heute einfacher und weitreichender ist: mit einem Klick kann man alle kategorisierten Daten, die man gesammelt hat, teilen und so das Leben der betroffenen Menschen entscheidend beeinflussen.
Diskriminierende Aspekte von Datensammlungen
Digitale Daten unterschiedlicher Personen werden unterschiedlich behandelt, ohne dass die Betroffenen davon wissen, sagte Rahman. Sie verwies auf ein ganz konkretes Beispiel zu diesem Thema: die sogenannte Gangs Matrix in Großbritannien. In dieser Datenbank wurden Daten von jungen, meist Schwarzen Männern im Vereinigten Königreich gesammelt. Hauptsächlich aufgrund des unbegründeten und ungerechtfertigten Verdachts, diese könnten Mitglieder einer Gang sein. Die höchst diskriminierende Sammlung persönlicher Daten beeinflusste den Alltag der Menschen negativ, während die Rechtfertigung für die Erfassung ihrer Daten wiederum auf rassistischen Vorurteilen beruhte. So wurden ihnen aufgrund einer Eintragung Jobs verwehrt oder Schulen nahmen die Kinder der Betroffenen nicht auf.
Hier liegt das Problem bei der Erfassung biometrischer Daten: Sie sind eng mit verschiedenen Faktoren verknüpft, z. B. mit dem Reisepass, der Hautfarbe oder sogar dem Flüchtlingsstatus.
Wiki Loves Folklore (WLF) ist ein internationaler Fotowettbewerb der Wiki-Community, der die Vielfalt der Volkskulturen unserer Welt feiert. Jedes Jahr vom 1. Februar bis 31. März sind Menschen weltweit mit Interesse an der Bewahrung von Kulturerbe dazu eingeladen, Impressionen rund um traditionelle Feste, Aufführungen, Tänze, saisonale Events, Märchen oder Sagen festzuhalten.
In den fünf Jahren des Bestehens hat WLF eine beeindruckende Sammlung von knapp 80 000 Mediendateien aus 168 Ländern zusammengetragen, zu denen rund 6500 engagierte Freiwillige einen unschätzbaren Beitrag geleistet haben. Die Fotos werden unter freier Lizenz bei Wikimedia Commons hochgeladen und können in der Wikipedia und an anderen Stellen verwendet werden.
2024 hat sich erstmals auch die deutsche Wiki-Community an „Wiki Loves Folklore“ beteiligt. „Die weltweiten vielfältigen Aspekte des immateriellen Kulturerbes sind eine wichtige Ergänzung zum Kultur- und Naturerbe, die wir schon seit vielen Jahren mit den Wettbewerben Wiki Loves Monuments (WLM) und Wiki Loves Earth (WLE) dokumentieren“, so die Wikipedia-Aktiven Ailura und z thomas in einemInterviewzum Start des Events.
Und die Resonanz aus Deutschland war groß: Knapp 800 Bilder und über 40 Videos sind bis zur Wettbewerbs-Deadline am 31. März eingereicht worden. Die Motive spiegeln die Vielfalt von Brauchtum in der Bundesrepublik.
Die Spanne reicht von derNubbelverbrennung(ein Brauch des rheinischen Karnevals, bei dem eine lebensgroße Strohpuppe als Verkörperung der Sünden verbrannt wird) über dasAnnotopia Festival(ein Fantasy-Festival, das deutschlandweit an mehreren Standorten gefeiert wird) bis zur festlichen Beleuchtung zumRamadan in Köln-Ehrenfeld.
Jetzt ist die Jury am Zug
Die hochgeladenen Fotos werden zunächst von einerVorjurybewertet. Ende Juni trifft sich eine Jury aus der Wiki-Community in Magdeburg, um daraus zehn Gewinnerbilder zu küren. Bewertet werden die Bilder unter anderem auf die Nützlichkeit des Bildes für die Wiederverwendung in der Wikipedia und ihren Schwesterprojekten, die technische Qualität und die Originalität. Wir sind gespannt auf das Ergebnis!
Dieser Artikel ist ursprünglich im Magazin “ausbildungsplatz-aktuell” erschienen.
Autor oder Autorin bei der Wikipedia? Schreiben da nicht nur alte Säcke und ewige Besserwisser? Nerds ohne Freunde? Nein, da irrst du dich ziemlich! Immer mehr junge Leute finden den Weg zur Enzyklopädie – nicht um zu lesen, sondern um sich zu beteiligen. Die meisten von ihnen bearbeiten oder schreiben Artikel, andere steuern Fotos bei oder erstellen Grafiken. Es gibt sehr viele Möglichkeiten, bei der Wikipedia mitzumischen. Vielleicht bist auch du ein Enzyklopädist?
Jungwikipedianer
Die jüngeren Mitarbeiterinnen und Mitarbeiter haben sich schon vor längerer Zeit zu den sogenannten Jungwikipedianern zusammengeschlossen. Sie haben eine eigene Seite im Universum der Wikipedia, wo etwas lockerer diskutiert wird. Mit der Zeit ist dort so manche Freundschaft entstanden. Um bei den Jungwikipedianern mitmachen zu können, musst du unter 21 Jahre alt sein und dich mit einem eigenen Benutzernamen anmelden. Du kannst auf den Diskussionsseiten der Jungwikipedianer auch immer mal aufschlagen, um Antworten auf deine Fragen zu bekommen.
Neugierig? Im Suchfeld der Wikipedia WP:JWP eintragen, dann bist du bei den Jungwikipedianern
(Fun)Facts über die Wikipedia
Die deutschsprachige Wikipedia hat fast 2,9 Millionen Artikel – nie hatte ein Lexikon deutscher Sprache mehr Einträge. Zum Vergleich: der berühmte „Brockhaus“ bringt es nur auf 300.000 Artikel. Würdest du die deutschsprachige Wikipedia ausdrucken, ergäbe das eine Bibliothek mit 1.700 Bänden, bestehend aus circa 1,5 Milliarden Wörtern. Damit könntest du ganz schön angeben!
Das Besondere der Wikipedia ist unter anderem, dass es die Enzyklopädie in mehr als nur einer Sprache gibt. Das war jetzt eine gigantische Untertreibung, denn die Wikipedia liegt in aktuell 339 Sprachversionen vor! Es gibt sie unter anderem auf Afrikaans, Esperanto, Nyanja (eine Sprache in Malawi) und Kalaallisut (eine Sprache im Westen Grönlands). Die größte Wikipedia ist die auf Englisch, was keine Überraschung ist. Aber welche Version liegt wohl auf Platz 2? Wir verraten es dir: es ist die Wikipedia auf Cebuano – das ist eine Sprache im Süden der Philippinen. Über sechs Millionen Artikel sind dort schon zu bestaunen.
Mentorenprogramm
Bevor du in der Wikipedia so richtig loslegst, ist es auch nützlich, die Seite des Mentorenprogramms zu kennen. Hier kannst du als Newbie einen erfahrenen Ansprechpartner finden, der dir in Rat und Tat zur Seite steht. Mit seiner – oder ihrer – Hilfe wirst du die ersten Schritte in der Wikipedia erfolgreich überstehen.
Startseite
Eine sehr gute Seite mit einer Einführung in viele Bereiche heißt: Wikipedia: Starthilfe. Neben Hilfen für Leser wirst du hier schrittweise an deine ersten Bearbeitungen herangeführt. Du findest hier auch einen Link zu Infos, was in Konfliktfällen zu tun ist. Für den Anfang ist diese Seite eine richtig gute Orientierung.
Was Wikipedia alles nicht ist
Von der Starthilfe-Seite aus kannst du viele weitere Themenfelder anklicken, die du am besten immer mal wieder in den Blick nimmst. Du lernst zum Beispiel, was Wikipedia alles nicht ist, z.B. kein Newsticker, keine Werbeplattform und kein Veranstaltungskalender. Und Wikipedia ist auch nicht der Ort, an dem du Essays schreibst und deine originellen
Gedanken verbreitest. Denn ein Grundsatz der Enzyklopädie lautet: Auf Wikipedia werden Theorien nicht ge- und erfunden, sondern dargestellt, und zwar auf der Grundlage guter Quellen.
Neutrale Darstellung
Apropos Grundprinzipien. So viele von denen gibt es gar nicht, aber ein Prinzip, auf das du immer achten solltest, ist die sogenannte neutrale Darstellung. Standpunkte von Ideologen gehören in kein Lexikon, sondern nur das, was aktueller Forschungsstand oder allgemein anerkannt ist.
Benutzernamen
Doch nun frisch ans Werk! Rein theoretisch kannst du in der Wikipedia unangemeldet editieren, also nur mit deiner IP-Adresse, aber empfehlenswerter ist es, sich mit Benutzernamen anzumelden. Beim Namen, also deinem Nick in der Wikipedia, kannst du deine Fantasie spielen lassen; die wenigsten editieren mit ihrem Klarnamen. Mit deinem Benutzernamen erhältst du eine eigene Benutzerseite mit dazugehöriger Diskussionsseite. Die ist sehr nützlich, wenn mal Meinungsverschiedenheiten auftreten oder sonst etwas zu klären ist.
Das Mentorenprogramm der Wikipedia findest du, indem du WP:MP in das Suchfeld eingibst.
Einfach zu finden unter: WP:START.
Immer mal wieder über das Suchfeld aufsuchen: WP:WWNI.
Weiteres zu diesem Thema unter WP:GP (Suchfeld).
Du brauchst Hilfe bei der Anmeldung? H:AM (Suchfeld) aufrufen.
So sehen sie aus, die Autorinnen und Autoren der Wikipedia! Vielleicht bist du schon bald dabei? In der Regel einmal pro Jahr treffen sie sich auf einer großen Konferenz namens WikiCon. Das Bild hier entstand 2023 im österreichischen Linz. Foto: Martin Kraft, MKr342205 Gruppenbild (WikiCon 2023 Linz), CC BY-SA 4.0.
So sehen sie aus, die Autorinnen und Autoren der Wikipedia! Vielleicht bist du schon bald dabei? In der Regel einmal pro Jahr treffen sie sich auf einer großen Konferenz namens WikiCon. Das Bild hier entstand 2023 im österreichischen Linz. Foto: Martin Kraft, MKr342205 Gruppenbild (WikiCon 2023 Linz), CC BY-SA 4.0.
Die ersten Bearbeitungen
Du brennst jetzt darauf, deinen ersten Artikel zu schreiben? So viel Schwung tut gut – dir und der Wikipedia! Ratsam ist aber, erst einmal einen schon vorhandenen Artikel zu bearbeiten. Eine angesagte Band hat ein neues Album herausgebracht, das in der Wikipedia noch nicht vermerkt ist? Die Einwohnerzahl deines Heimatortes könnte mal auf den neuesten Stand gebracht werden? Nur zu! Und wenn Du allmählich weißt, auf was zu achten ist, steht deinem ersten eigenen Artikel nichts mehr im Wege.
Aber über was soll ich überhaupt schreiben?
Eine gute und natürlich auch wichtige Frage! Wenn du genau überlegst, werden dir schnell Themen einfallen, die dich interessieren. Nicht alle Spieler deines Lieblingsvereins haben einen Artikel? Du beschäftigst dich mit Biologie und willst über Tiere und Pflanzen schreiben? Ganz im Gegenteil, eher Computerspiele haben es dir angetan? Es ist immer ein Vorteil, wenn man sich in einer Materie schon ein wenig auskennt und nach seriösen Quellen nicht lange suchen muss. Zu beachten ist allerdings, dass nicht alle Themen für die Wikipedia in Frage kommen. Omas Hamster, in der Wikipedia ein sprichwörtliches Beispiel, überspringt z.B. nicht die sogenannte Relevanzhürde. Wenn du dir unsicher bist, wer oder was in das Lexikon gehört, kannst du gerne andere Jungwikipedianer oder deinen Mentor um Rat fragen.
Frauen in Rot
Nur 18 Prozent aller Biografien in der Wikipedia sind Frauen gewidmet – eine viel zu niedrige Zahl! Deshalb gibt es innerhalb der Wikipedia die Initiative „Frauen in Rot“, die es sich zum Ziel setzt, Frauen sichtbarer zu machen. Auch hier bist du gerne gesehen: Wenn du über eine Menschenrechtsaktivistin, eine Malerin oder ein Model einen Artikel anlegen willst, darfst du mit Unterstützung rechnen. „Frauen in Rot“ bedeutet übrigens, dass diese Frauen nur einen Rotlink haben, was bedeutet, dass der Artikel fehlt. Sobald der Artikel geschrieben ist, wird der Link blau.
Immer nützlich: die Seiten H:SB und H:NA (über Suchfeld).
Und unter WP:RELC (Suchfeld) kannst du einen „Relevanzcheck“ machen.
WP:FRAUROT freut sich über deinen Besuch.
Schreiben ist nicht dein Ding? Kein Ding!
Auch als Fotograf oder Fotografin kannst du zu der Online-Enzyklopädie beitragen und ein Teil der Bewegung sein, die weltweit freie Inhalte und freies Wissen zur Verfügung stellt.
Fotos werden auf Wikimedia Commons (einfach mal bei Google eingeben) hochgeladen. Dort findest du alles Weitere unter der Überschrift „Mitmachen”.
Viel Spaß!
Lerne das größte Mitmach-Projekt des Planeten kennen!
Du wolltest schon immer mal wissen, wie die Wissens-Gigantin Wikipedia eigentlich funktioniert und was sich hinter den Kulissen abspielt?
Dann ist dies deine Challenge. In 30 E-Mails mit 30 Missionen bekommst du Einblick in einen Kosmos aus Millionen Freiwilligen, einer außerordentlichen Geschichte, globalen Strukturen und einem Ziel: Das gesamte Wissen der Menschheit für alle Menschen auf der Welt frei verfügbar zu machen.
Open Government Data, also Informationen der öffentlichen Hand, die von allen zu jedem Zweck frei genutzt, wiederverwendet und weiterverbreitet werden können, sind längst kein Nischenthema mehr. Spätestens durch die Überarbeitung der Open-Data-Richtlinie der Europäischen Union und die Durchführungsverordnung über hochwertige Datensätze hat die EU klargestellt: Staat und Verwaltung sollen ihren Wissensschatz wiederverwendbar veröffentlichen, sofern nicht personenbezogene Informationen oder Geheimnisse darunter fallen. Die europäischen Gesetzgeber haben dabei in mehreren Rechtsakten ausdrücklich die bevorzugte Verwendung bestimmter CC-Lizenzen empfohlen.
Woher die Vorbehalte gegen CC-Lizenzen kommen
In Deutschland hält sich seit 2012 die Ansicht, dass staatliche Stellen die CC-Lizenzen nicht verwenden können oder dürfen. Der Grund dafür: Eine Studie im Auftrag des Bundesministerium des Innern, die unter anderem behauptete, dass bestehende, etablierte Lizenzen nicht passgenau für den deutschen Rechtsrahmen seien. Sie empfahl die Entwicklung einer eigenen Datenlizenz. Das Ergebnis war die „Datenlizenz Deutschland“. Seither entwickelte Empfehlungen oder Vorgaben zur Veröffentlichung staatlicher Informationen unter der „Datenlizenz Deutschland“ greifen immer wieder auf die Thesen des Gutachtens von 2012 zurück. 2019 kam ein weiteres Gutachten im Auftrag des Landes Nordrhein-Westfalen hinzu, das jedoch nur Bezug auf die Creative-Commons-Lizenzversion 3.0 zu nehmen schien, obgleich seit 2013 die aktuelle Lizenzversion 4.0 existiert, die Kritikpunkte der Vorversion weitestgehend ausgeräumt hat.
Um die bestehenden Vorbehalte gegen die Verwendung von CC-Lizenzen auf ihre Stichhaltigkeit zu prüfen und staatlichen Akteur*innen mehr Rechtssicherheit zu verschaffen, hat Wikimedia Deutschland daher die Anwaltskanzlei TaylorWessing beauftragt, zu prüfen: Gibt es tatsächlich Gründe, die gegen die Nutzung von CC-Lizenzen durch öffentliche Stellen in Deutschland sprechen? Denn die Verwendbarkeit verschiedener Datensätze über nationale Grenzen hinweg ist schließlich erklärtes Ziel von Open Data und auch der Open-Data-Rechtsakte der EU. Das geht dann besonders gut, wenn Nutzende vor der Wiederverwendung nicht erst verschiedenste nationale Lizenzen analysieren müssen.
Wesentliche Erkenntnisse aus dem neuen Rechtsgutachten
Die Vorgaben der europäischen Open-Data-Gesetzgebung empfehlen durchgehend und explizit die Verwendung der Creative-Commons-LizenzenCC BY 4.0 und CC0 1.0 „oder gleichwertiger Lizenzen“
Nach deutschem Recht bestehen keine relevanten rechtlichen Bedenken gegen die Verwendung der Creative-Commons-Lizenzen durch die öffentliche Hand. Insbesondere die immer wieder vorgebrachten Einwände wegen der Gewährleistungs- und Haftungsklauseln haben keine praktische Relevanz.
Die Creative-Commons-Lizenzen bieten durch ihr „Drei-Schichten-Modell“ mit Kurzfassung, ausführlichem Vertragstext und maschinenlesbarer Komponente ein ausgereiftes Lizenzierungsmodell, das durch Auslegungshilfen und laufende Rechtsprechung ein hohes Maß an Rechtssicherheit bei der Verwendung bietet.
Die aktuellen zwei Varianten der Datenlizenz Deutschland (DL-DE) bestehen nur in einer Kurzfassung, die offene Fragen und Auslegungszweifel hinterlässt – insbesondere zur Frage, ob sie aufgrund von Urheber- bzw. sonstigen Schutzrechten gelten oder durch einen behördlichen Widmungsakt. Ihre Gleichwertigkeit zu den Creative-Commons-Lizenzen kann angezweifelt werden. Außerdem bestehen Zweifel am Bedarf für diese Lizenz, die in erster Linie auf Datenpunkte ausgerichtet ist, welche jedoch nach geltendem Recht gerade keinem Urheberschutz unterliegen.
Die Open-Data-Commons-Lizenzen kommen nur für die Lizenzierung von Datenbanken in Betracht, so dass für die Lizenzierung beispielsweise von Sprachwerken weitere Lizenzen notwendig sind. Ein Mehrwert gegenüber der Verwendung der Creative-Commons-Lizenzen ist nicht ersichtlich.
Für Kenner*innen der Rechtsdogmatik kommen diese Ergebnisse wenig überraschend. Das TaylorWessing-Gutachten deutet an, dass die Vorbehalte im Wesentlichen auf die 2012 vom BMI beauftragte Studie zurückgingen. Allerdings wurden die CC-Lizenzen seit 2012 weiterentwickelt. Zum Zeitpunkt des Gutachtens lagen die CC-Lizenzen noch in der Version 3.0 vor, die in die jeweiligen nationalen Rechtsrahmen „portiert“ werden mussten. Mit der aktuellen Version 4.0 ist dies nicht mehr notwendig. 2012 bestand offenbar auch der staatliche Wunsch, eine Lizenz mit verpflichtender Namensnennung durch amtliche Widmung anwenden zu können, selbst wenn es sich bei dem zu lizenzierenden Gegenstand gar nicht um urheberrechtlich geschütztes Material handelt.
Die verschiedenen existierenden Positionspapiere von Arbeitsgruppen und staatlichen Stellen scheinen sich dabei stets aufeinander und dann letztlich auf die BMI-Studie von 2012 zu beziehen, ohne die dort aufgestellten Thesen zu hinterfragen – beispielsweise, welche rechtliche Bindungskraft eine per Widmungsakt einer deutschen Behörde angewandte Lizenz für Wiederverwender*innen so lizenzierter Daten in Italien oder Österreich haben soll.
Auch das immer wieder als Problem vorgebrachte Thema der Amtshaftung scheint im Ergebnis keine Rolle zu spielen. Die Creative-Commons-Lizenzen schließen zwar standardmäßig jegliche Gewährleistung und Haftung aus – was im deutschen Rechtsraum nicht zulässig ist. In der Konsequenz greift hier schlicht die gesetzliche Regelung, die zu einer begrenzten Gewährleistung bzw. Haftung der Daten bereitstellenden Stellen führt. Das TaylorWessing-Gutachten macht auch einen Formulierungsvorschlag, wie eine Behörde den Verzicht auf den in der Lizenz vorgesehenen Gewährleistungs- und Haftungsausschluss erklären kann, um dies eindeutig klarzustellen.
Die europäischen Empfehlungen sprechen indes eine klare Sprache: Informationen der öffentlichen Hand sollen die vorgeschlagenen CC-Lizenzen „oder gleichwertige Lizenzen“ verwenden. Der Datenlizenz Deutschland fehlt jedoch eine nachvollziehbare rechtliche Definition – inklusive der Beschreibung, auf welcher Rechtsgrundlage sie auch außerhalb der Bundesrepublik und der Rechtskraft eines behördlichen Widmungsakts gelten könnte. Sie enthält außerdem keine maschinenlesbare Komponente, die eine Gleichwertigkeit mit Creative Commons herstellen würde. Aus Sicht von Wikimedia Deutschland bestärkt das Gutachten von TaylorWessing, dass es keinen Anlass gibt, den Empfehlungen der EU nicht zu folgen.
Wie lässt sich das Beste aus den eigenen Daten machen? Vor dieser Frage stehen schon seit langem sämtliche der Kulturerbe-Institutionen, die über die Ressourcen und das Knowhow für die Digitalisierung ihrer Sammlungen verfügen. Wobei sich immer mehr die Erkenntnis durchsetzt, dass es nicht ausreicht, Digitalisate der Sammlungen nur auf der Homepage zur Verfügung zu stellen, wo gezielt suchende Interessierte sie finden und downloaden können. Zumindest dann nicht, wenn eine Institution die vollen Potenziale des Internets nutzen und sich die Frage stellt: Was könnte mit digitalem Kulturerbe möglich werden – vor allem, wenn es verlinkte offene Daten sind?
Wie das Prinzip Linked Open Data funktioniert
Das Prinzip der Linked Open Data (LOD) steht für das Gegenteil der unter Kulturinstitutionen lange verbreiteten Haltung, Hüter*innen der Schätze zu sein. Es geht darum, Datensets offen verfügbar zu machen – und zwar so, dass die Werke oder Artefakten, die sie beschreiben, automatisiert aufgefunden werden können. Gerade auch von Menschen, die nicht schon wissen, in der Datenbank welcher Institution genau sie nach den Informationen, die sie benötigen, suchen sollen.
Grundlage für Linked Open Data sind die Ideen und Techniken des sogenannten Semantic Web. Tim Berners-Lee, Begründer des World Wide Web, hat es so beschrieben: „Das Semantic Web ist eine Erweiterung des herkömmlichen Webs, in der Informationen mit eindeutigen Bedeutungen versehen werden, um die Arbeit zwischen Mensch und Maschine zu erleichtern“ („The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation“). So kann beispielsweise das Wort „Bremen“ in einem Webdokument um die Information ergänzt werden, ob hier der Begriff des Schiffs-, Familien- oder Stadtnamens gemeint ist. Was für den Computer vormals nur Zeichenketten waren, wird auf diese Weise zu berechenbarer Bedeutung.
Wenn wir von verknüpften Daten sprechen, meinen wir strukturierte Daten, die mit anderen Daten verknüpft sind – was bedeutet, dass die Verbindungen zwischen Datensätzen sowohl für Maschinen als auch für Menschen verständlich sind. Diese Verknüpfungen können zwischen bestimmten Dingen – zum Beispiel Ereignisse, Personen oder Orte – hergestellt werden, auf die sich die Datensätze beziehen. Tim Berners-Lee hat vier Gestaltungsprinzipien für Linked Data beschrieben. Erstens: Die Verwendung von URIs (Uniform Resource Identifiers), um den Dingen eindeutige Namen zu geben. Zweitens sollten diese URIs mit Hilfe eines HTTP-Protokolls online auffindbar gemacht werden. Drittens: Die Art und Weise, wie Informationen über diese URIs bereitgestellt werden (unter Verwendung von RDF und SPARQL für Abfragen) muss standardisiert sein. Und schließlich sollten in diese Informationen Links zu anderen URIs aufgenommen werden. Durch diese Verknüpfung werden alle möglichen Dinge in einem Netz miteinander verbundener Daten – einem so genannten Wissensgraphen – verlinkt.
Verknüpfte Daten sind besonders wertvoll, wenn sie nach dem Konzept der offenen Daten kombiniert werden. Das heißt: Daten, die für jeden offen und unter einer freien Lizenz zugänglich sind. Wo schon verknüpfte Daten Datensilos aufbrechen, indem sie die Verbindungen zwischen Datensätzen maschinenlesbar machen, bricht die offene Lizenzierung dieser verknüpften Daten die Silos noch weiter auf – indem sie es jedem ermöglicht, auf sie zuzugreifen, sie wiederzuverwenden und somit auch zu verknüpfen und abzufragen. Was zum Wachstum eines globalen Wissensgraphen beiträgt. Entsprechend wertvoll ist das Prinzip beispielsweise für Kultureinrichtungen, die im öffentlichen Interesse Daten anbieten wollen, anstatt sie nur in geschlossenen und proprietären Datenbanken zu verwahren oder ausschließlich über eigene Interfaces anzubieten, wo sie nicht nachgenutzt werden können.
Ein Bestimmungsmaß für die Qualität von LOD bieten die FAIR Guiding Principles for scientific data management and stewardship, die 2016 als Artikel in der Fachzeitschrift Nature veröffentlicht wurden. FAIR steht als Akronym für die Auffindbarkeit (Findability), Zugänglichkeit (Accessibility), Interoperabilität (Interoperability) und Wiederverwendbarkeit (Reuse) wissenschaftlicher Daten.
Wenn komplexe Realitäten maschinenlesbar werden
Wie aber können Kulturinstitutionen Linked Open Data aufbauen? Um verschiedene Menschen, Orte, Dinge oder Konzepte in Daten zu repräsentieren und sie auffindbar zu machen, braucht es eindeutige Referenzen. Das „Bildnis eines Musikers” (Portrait of a Musician) von Leonardo da Vinci zum Beispiel ist auch unter dem Titel „Bildnis eines jungen Mannes“ bekannt – und beide Titel sind wiederum auch von anderen Künstler*innen verwendet worden, so wie es eine Vielzahl von Gemälden namens „Madonna mit Kind“ gibt. Um die eindeutige Zuordnung zu ermöglichen, braucht man eindeutige Identifier – wiederum laut Tim Berners-Lee eines von vier Prinzipien für Linked Data, die möglichst international anerkannt sein sollten.
In der Bibliothekswelt – wo Einrichtungen vielfach über die gleichen Titel verfügen und Leihen zwischen Bibliotheken gang und gäbe sind – ergibt es schon seit langem Sinn, ein geteiltes System von eindeutigen URIs zu haben. Das bekannteste Beispiel in Deutschland ist in diesem Zusammenhang die Gemeinsame Normdatei (GND) der Bibliotheken, die von der Deutschen Nationalbibliothek (DNB), allen deutschsprachigen Bibliotheksverbänden, der Zeitschriftendatenbank (ZDB) und zahlreichen weiteren Institutionen kooperativ geführt wird. Ähnliche Normdateien – im Englischen „authority files“ – existieren für Wissenscommunitys in verschiedenen Ländern und Regionen genauso wie für verschiedene Disziplinen und Wissensbereiche.
Um nun wiederum die Beziehung zwischen Datenobjekten („Items“) zu beschreiben – etwa zwischen Künstler*in und Werk – braucht es in der Welt der Daten eine Ontologie. Kurzgefasst: eine Methode, die eingrenzt, wie die Welt in reduzierter Weise beschreibbar wird. Schließlich bilden Daten die Realität nie in ihrer Gesamtheit ab, sondern müssen sie bis zu einem bestimmten Grad vereinfachen. Ein Beispiel für eine Ontologie ist der LIDO-Standard in Museen („Lightweight Information Describing Objects“), ein Schema zum Austausch von Metadaten von Sammlungsobjekten. Es zielt darauf, auch komplexere Zusammenhänge etwa bezüglich der Entstehung eines Kunstwerks zu fassen – wenn ein Bild beispielsweise keinem konkreten Jahr zugeordnet werden kann, weil es zu einem bestimmten Zeitpunkt begonnen, aber erst später fertiggestellt wurde.
Die Beziehungen zwischen Datenobjekten müssen nach dem LOD-Prinzip maschinenlesbar sein. Die Maschine muss verstehen, worum es sich (um im Beispiel zu bleiben) bei Leonardo da Vinci und seinen Kunstwerken handelt. Verdeutlich wird das über sogenannte Triples aus Subjekt-Prädikat-Objekt. Über ein solches Triple lässt sich etwa die Aussage treffen: Leonardo da Vinci ist ein Mensch. Das Subjekt: Leonardo da Vinci. Das Objekt: Mensch. Das Prädikat, das die Beziehung darstellt: ist ein. Auf diese Weise werden Daten aus den verschiedensten Datenbanken rund um die Welt durchsuchbar.
Wie Wikidata die Welt verbindet
Zu diesen Datenbanken zählt seit 11 Jahren Wikidata, die freie Datenbank von Wikimedia. Wikidata ist längst ein wichtiger Hub für LOD geworden. Ein Ort, wo Normdateien aus allen Teilen des World Wide Web zusammenkommen, Knotenpunkte bilden, aufeinander verweisen und sich mit anderen URIs verlinken. Das Alleinstellungsmerkmal von Wikidata ist genau diese Vernetzung disparater Datenquellen.
Als Beispiel soll das Wikidata-Item der mexikanischen Malerin Frida Kahlo dienen. Ihr Wikidata-Eintrag ist gekennzeichnet mit der Nummer Q5588. Diese Nummer entspricht in Linked-Open-Data-Begriffen dem URI – ein online auffindbarer, eindeutiger und einzigartiger Identifier. Die Triple-Statements, die Aussagen über Frida Kahlo treffen, werden in der Wikidata-Terminologie nicht über Subjekt-Prädikat-Objekt, sondern über „Item-Property-Value“ abgebildet. Wie die Aussage über ihre Staatsbürger*innenschaft: „Country of Citizenship: Mexico“ (Item: Frida Kahlo, Property: Citizen of, Value: Mexico). Um Statements noch spezifischer zu machen, kommen sogenannte Qualifier ins Spiel. Der Aussage „Cristina Kahlo y Calderón ist Frida Kahlos Schwester“ wird hinzugefügt: „jüngere Schwester“.
Screenshot des Wikidata-Eintrags „Frida Kahlo“
Frida Kahlos Eintrag in Wikidata listet aber vor allem eine große Zahl externer Identifier auf: von VIAF (Virtual International Authority File) über die „National Library of Brazil“, die „National Library of Chile“ und die GND bis hin zu abseitigeren wie ihrer „Good Reads Author ID“ (mit 987 Followern) oder Frida Kahlos „Twitter username“. Wer einen Überblick bekommen möchte, in welchen Sammlungen rund um die Welt die Werke von Frida Kahlo zu finden sind und welche Datenbanken Informationen über die Künstlerin bieten, wird auf Wikidata fündig.
Generell ist dies die Idee von Linked Open Data im Kontext von Kultur: Daten global auffindbar zu machen – schließlich besitzt Kultur globale Relevanz – und mit LOD z.B. die Verfolgung des Wegs bestimmter Künstler*innen oder Autor*innen zu ermöglichen, gerade, wenn sie in verschiedenen Ländern gearbeitet haben. Weiter gefasst könnten auch die Bewegung von Kunstwerken zwischen Händler*innen und Institutionen aufspürbar und nachvollziehbar werden. Auch von solchen, die etwa in kolonialen Kontexten geraubt wurden – sofern die Informationen über sie als LOD geteilt sind.
Wie Institutionen eine neue Rolle einnehmen können
Linked Open Data bieten Kulturerbe-Institutionen im Internet-Zeitalter die Möglichkeit, neue Verbindungen zur Welt aufzubauen und neue Zugänge zu schaffen. Die Einrichtungen können mit einem globalen Publikum in Kontakt kommen, das sich für die Geschichten interessiert, die sie sammeln und bewahren, sie können diese Geschichten global teilen und neue Formen der Kollaboration erproben, sie können dafür sorgen, dass ihre Geschichten sich mit den Geschichten der Welt verbinden. Daraus lassen sich wertvolle Schlüsse und Erkenntnisse ziehen – nicht zuletzt über die eigene Rolle. Die Kultureinrichtungen haben die Chance, eine neue Position einzunehmen: als Akteur*innen in den globalen Commons.
Der erste Schreibwettbewerb in der deutschsprachigen Wikipedia fand bereits im Oktober 2004 statt. Die Resonanz darauf war so groß, dass die Community entschied, das Event zweimal jährlich abzuhalten – jeweils im März und September.
In den bisherigen Ausgaben wurden knapp 2030 Artikel eingereicht, von denen sich rund die Hälfte in der Top 10 des Wettbewerbs platzieren konnte. Außerdem wurde ein Großteil der teilnehmenden Texte mit einem Qualitätsprädikat bedacht – der Ritterschlag der Community für besonders gelungene Artikel. Mehr als ein Viertel aller Einreichungen sind inzwischen zum„exzellenten Artikel“geworden – die höchste Auszeichnung überhaupt –, ein Sechstel wurde als„lesenswerter Artikel“eingestuft.
Aus diesem Pool der exzellenten und lesenswerten Beiträge stammt auch jeweils der „Artikel des Tages” auf derHauptseiteder freien Online-Enzyklopädie.
Auf dem Weg zur Top 10
Noch bis zum 31. März findet die mittlerweile40. Ausgabe des Schreibwettbewerbsstatt. Die Teilnehmer*innen können ihre Artikel in drei Kategorien einreichen: „Natur und Technik”, „Kunst und Kultur” sowie „Geschichte und Gesellschaft”. Für jede der Kategorien wurden zwei Juror*innen aus der Community bestimmt. Während des laufenden Wettbewerbs findet außerdem eineReview der Artikeldurch engagierte Wikipedianer*innen statt, die hilfreiche Tipps geben. Denn obwohl es ein Wettbewerb ist, soll nicht der Konkurrenzgedanke im Vordergrund stehen, sondern der Spaß am Schreiben für die Wikipedia.
Nach Ablauf der Wettbewerbsfrist erstellen die Juror*innen eine gemeinsame Rangliste der besten Artikel aller Sektionen, aus der schließlich die Gewinner-Top-10 hervorgeht. Darüber hinaus wird auch einPublikumspreisvergeben. Zu gewinnen gibt es Büchergutscheine oder eine Wikipedia-Powerbank.
Nosferatu und die Schwarze Witwe
Unter den bisherigen Einreichungen zum 40. Schreibwettbewerb finden sich beispielsweise Artikel über dieSüdliche Schwarze Witwe– eine besonders gefährliche Giftspinne –, die Schweizer Ringkampf-VarianteSchwingenoder dieUngarische Räterepublik, die vor 105 Jahren ins Leben gerufen wurde.
Der Fotowettbewerb Wiki Loves Monuments findet jährlich im September statt und wird von Mitgliedern der Wikimedia-Communitys auf der ganzen Welt organisiert. Die Teilnehmer*innen fotografieren historische Denkmäler und Kulturerbe-Stätten in ihrer Region und laden sie unter freier Lizenz im Medienarchiv Wikimedia Commons hoch. Erstmals war 2023 auch eine Wikimedia User Group der afrikanischen Ethnie Igbo dabei.
Aufgrund des Engagements der über 4.700 Teilnehmenden aus 46 Ländern konnte Wikimedia Commons um knapp 219.000 Bilder wachsen. Die Gewinner*innen der nationalen Wettbewerbe wurden bereits ausgezeichnet (die Top-Bilder aus Deutschland finden Sie hier). Bis zu zehn Bilder aus jedem dieser Wettbewerbe konnten für das internationale Finale nominiert werden. Jetzt hat die Jury die schönsten Fotos gekürt. Platz 2 ging nach Deutschland.
Der erste Platz kommt aus Ägypten. Die Aufnahme von den Pyramiden von Gizeh hat die Fotografin Mona Hassan Abo-Agda geschossen. Die Jury schreibt dazu: „Das Foto veranschaulicht den Mehrwert von Kunstwerken zu bestehenden Monumenten und die Synergie, die zwischen den beiden entstehen kann. Der Winkel und die Entfernung des Bildes wurden sehr gut gewählt, um eine ausgewogene und proportionale Szene zu schaffen.“
Diese Aufnahme zeigt das Schloss Marksburg in Braubach. Fotograf Rolf Kranz hat mit seinem Foto auch die deutsche Wiki Loves Monuments-Runde gewonnen. Die Marksburg hat die Zeit überdauert und war Zeuge von Kriegen, politischen Intrigen und sozialen Veränderungen in der Region. Die Gegenüberstellung der alten Burg mit den modernen Industrieschornsteinen im Hintergrund hebt den Kontrast zwischen Vergangenheit und Gegenwart hervor. Die Jury sagt dazu: „Sehr gut ausbalanciert, dient die Linie des Rauches als Verbindung zwischen den beiden Gebäuden und erzeugt den Effekt einer Interaktion zwischen der Gegenwart (verkörpert durch die Fabrik) und der Vergangenheit (verkörpert durch das Schloss).“
Der 3. Platz zeigt das Bergdorf Premana in Italen. „Das Foto fängt die Synergie zwischen der natürlichen und der vom Menschen geschaffenen Umgebung perfekt ein und veranschaulicht die Lage des Dorfes in den Bergen. Der weiche Kontrast zwischen dem späten Abendhimmel und den Lichtern des Hauses verleiht der Komposition des Dorfes viel Wärme und Kraft“, so die Jury.
Wer nun Lust bekommen hat, selbst die Kamera in die Hand zu nehmen, kann sich schon mal in Vorfreude üben. Auch im Herbst 2024 rufen die Ehrenamtlichen der Wikipedia und des freien Medienarchivs Wikimedia Commons wieder dazu auf, Aufnahmen von Denkmälern zu machen und beim Wiki Loves Monuments-Wettbewerb einzureichen. Über die Details berichten wir zeitnah hier im Wikimedia-Blog und auf unseren Social Media-Kanälen.
Lust auf weitere tolle Fotos?
Alle internationalen Gewinnerbilder sowie die nominierten Beiträge der Wiki Loves Monuments-Wettbewerbe aus den vergangenen Jahren finden Sie hier:
Transparenz, Bürgerbeteiligung und freier Zugang zu Informationen sind grundlegende Aspekte für eine demokratische Gesellschaft, die sich besonders gut durch digitale Anwendungen realisieren lassen. Die Agora Digitale Transformation argumentiert auf ihrer Website, dass die Stabilität der Demokratie davon abhängt, wie digitale Technologien im Interesse der Bürger*innen genutzt werden. Sie fordert daher ein Update dieser Technologien. Auch Franziska Heine, neben ihrer Tätigkeit bei Wikimedia Deutschland im Arbeitskreis gegen Internetsperren und Zensur aktiv, sieht eine sorgfältige Digitalisierung als Chance, um die Stabilität eines modernen demokratischen Staates zu erhöhen.
Hallo Franziska, du hast lange die Software-Entwicklung bei Wikimedia Deutschland geleitet, die offene und freie Software baut. Du setzt dich schon lange für gemeinnützige Digitalisierung ein – wenn du aus diesen beiden Perspektiven auf die aktuelle Digitalpolitik blickst – was sollte sich ändern?
Eine offene, freie, selbstverwaltete digitale Infrastruktur wird in Zukunft, mehr denn je, ein entscheidender Faktor für eine erfolgreiche Wirtschaft, einen handlungsfähigen Staat und eine freie Gesellschaft sein. Wir sind in Deutschland dafür sogar bereits gut aufgestellt; nur wird das noch nicht ausreichend genutzt. Es gibt inzwischen viele freie Software- und Datenprojekte wie Nextcloud, Mastodon, OpenStreetMap, LibreOffice, Linux Varianten und nicht zuletzt unsere eigenen Projekte wie Wikipedia und Wikidata. Wesentliche Bestandteile einer freien und offenen Infrastruktur sind ebenfalls vorhanden. Es gibt viele Freiwillige im digitalen Ehrenamt, zum Beispiel bei der Wikipedia, die seit Jahrzehnten beweisen, wie stabil und zuverlässig nicht-kommerzielle Infrastrukturen betrieben werden können.
Was sich daher ändern muss, ist der politische Wille zur digitalen Souveränität – dass wir uns nicht mehr bei digitalen Belangen auf große kommerzielle Unternehmen verlassen, sondern gemeinnützige Projekte einsetzen, die für mehr Sicherheit, Transparenz und Beteiligung sorgen. Natürlich hängt da sehr viel Arbeit und Investition dran, das bestehende System der proprietären Abhängigkeit zu verlassen und den Mut zur digitalen Freiheit zu haben. Gleichzeitig gibt es aber so viele gute Gründe, dieses Abenteuer zu wagen, denn die Alternative ist eine Abhängigkeit von Big Tech, größtmöglicher Intransparenz und das unkontrollierbare Absaugen der Daten unseres Verwaltungsapparates und Bürger*innen.
Welche Chancen bietet die Digitalisierung aus deiner Sicht für die Demokratie?
Wenn Digitalisierung erfolgreich umgesetzt wird, ermöglicht sie mehr Menschen den Zugang zu für sie relevanten Informationen. Es können neue Werkzeuge entstehen, die ihnen ganz praktisch den Alltag erleichtern, aber eben auch Behörden und staatliche Institutionen in ihrer Arbeit effizienter und wirksamer machen. Menschen können an mehr Prozessen auf die für sie passende Art beteiligt werden. An Entscheidungsprozessen zum Beispiel oder daran, ihre ganz konkrete Umwelt lebenswerter mitzugestalten. Ein schönes Beispiel dafür sind die Projekte des CityLAB Berlin wie giessdenkiez.de, bei denen eine Kombination aus Verwaltungsdaten, in diesem Fall Geoportal Berlin der Senatsverwaltung, OpenStreetMap als Community Projekt und freie Software gemeinsam mit der Kiez Community in der realen Welt einen Beitrag leisten. giessdenkiez.de gibt Bürger*innen die Möglichkeit Straßenbäume zu adoptieren und regelmäßig zu gießen, damit diese nicht der durch den Klimawandel entstandenen Trockenheit zum Opfer fallen. Das ist ein tolles Projekt der Stadt Berlin, das alle drei Akteure digital miteinander verbindet.
Warum ist ein Thinktank wie die Agora Digitale Transformation wichtig und was kann die Initiative zu einer gelungenen Digitalpolitik beitragen?
Der Thinktank ist wichtig, weil er auf einzigartige Weise Politik, Forschung, Verwaltung, Wirtschaft und die Zivilgesellschaft zusammenbringt. Es ist der Initiative gelungen, unglaublich tolle und kompetente Menschen aus all diesen Bereichen im Thinktank zu versammeln. Das zeigte sich besonders eindrücklich in der Interaktion und den Redebeiträgen während der konstituierenden Sitzungen des Beirats. Dort werden die Konzepte und Ideen der Projektarbeit des Thinktanks mit den Realitäten von Ministerialbürokratie, zivilgesellschaftlichen Perspektiven und wirtschaftlichen Gegebenheiten konfrontiert.
Der Rat der Agora Digitale Transformation ist nun am 12. März, das erste Mal zusammengetreten – wie ist die erste Sitzung gelaufen? Kannst du uns verraten, um welche Themenschwerpunkte es ging?
Zunächst einmal haben wir das Team besser kennengelernt, das über die letzten Monate aufgebaut wurde und seine Arbeit an verschiedenen Projekten aufgenommen hat. Zwei der gestarteten Projekte haben Einblicke in ihre Arbeit gegeben und die Mitglieder des Beirats eingeladen, Fragen zu stellen und Feedback zu geben.
Das Projekt “E-Valuate” beschäftigt sich damit, die Arbeit an ministeriellen Projekten wirkungsorientierter zu gestalten und mithilfe von OKRs messbarer zu machen. OKRs steht für Objectives and Key Results, also Zielsetzungen und Schlüsselergebnisse und stellt ein Management-Framework dar, das speziell auf die sich permanent verändernden Rahmenbedingungen unserer modernen Welt zugeschnitten ist. Das Projekt steht damit ganz unter dem Motto „Lernender Staat“. Das zweite Projekt geht der Frage nach, wie viel Geld die Bundesregierung in den letzten Jahren für die Digitalisierung der Verwaltung ausgegeben hat. Auch dazu gab es regen Austausch.
Jenseits dieser beiden Schwerpunkte haben wir uns in den Pausen auch über zivilgesellschaftliche Perspektiven auf die Verwaltungsarbeit, Zukunftsfragen des öffentlich-rechtlichen Rundfunks und spannende Podcasts unterhalten.
Was wirst du im Austausch mit den anderen Ratsmitgliedern beitragen? Was wird deine Rolle sein?
Zum einen werde ich die Perspektive der Zivilgesellschaft vertreten. In unseren Projekten tragen täglich viele Ehrenamtliche dazu bei, das Wissen über unsere Welt zu dokumentieren und allen zugänglich zu machen. Gleichzeitig haben sie in ihrer Zusammenarbeit über zwei Jahrzehnte Strukturen und Aushandlungsprozesse entwickelt, die transparent und zutiefst demokratisch sind und teilweise sehr komplexe Herausforderungen lösen. Ich würde mir wünschen, dass dieser Aspekt der Arbeit, die in unseren Projekten geleistet wird, mehr Aufmerksamkeit bekommt, weil ich glaube, dass sie als Modelle für eine resiliente Demokratie dienen können.
Zum anderen bringe ich unsere Expertise in der nachhaltigen Entwicklung von Open-Source-Softwarelösungen mit. Wikipedia und Wikidata sind lebende Beispiele dafür, dass es möglich ist, offene und freie Software-Systeme nachhaltig zu entwickeln und zu betreiben. Wir gehören noch immer zu den 10 meistbesuchten Webseiten der Welt, unsere Daten werden von allen großen digitalen Innovationen der letzten Jahrzehnte genutzt. Unter anderem von Google, persönlichen Assistenten und generativer KI, basierend auf Large-Language-Modellen. Wir sind sozusagen der lebende Beweis dafür, dass es weder notwendig noch richtig ist, auf proprietäre Softwarelösungen zu setzen und diesen Punkt werde ich natürlich stark machen, wenn es um die Digitalisierung der Verwaltung geht.
Der dritte Aspekt sind freie und offene Daten: Wenn wir unsere Demokratie transformieren wollen, dann gehört der Freie Zugang zu den Daten, die unsere Demokratie produziert, dazu. Wir haben mit der freien Wissensdatenbank Wikidata und der Open-Source-Software Wikibase inzwischen erprobt, wie gut das funktionieren kann.
Vielen Dank für das interessante Gespräch.
Der Thinktank wird von der Stiftung Mercator gefördert und arbeitet in verschiedenen Projekten an Lösungen für die Digitale Transformation in den Themenfeldern “Lernender Staat”, “Digitale Öffentlichkeit”, “Digitale Partizipation” und “Regierungshandeln & Digitalisierung”. Die Ergebnisse werden dem Rat, der Feedback gibt, über mehrere Sitzungen vorgelegt. Alle Projekte zielen darauf ab, praxisorientierte Handlungsempfehlungen für die Politik zu entwickeln.
Natürlich kann man die Wikipedia nicht einfach abschalten. Die Online-Enzyklopädie ist ein Projekt der ehrenamtlichen Community. Die handelt gemeinsam Regeln und Entscheidungen aus. So war es auch, bevor am 21. März 2019 der freie und digitale Zugang zu Wissen für einen Tag lahmgelegt wurde. In einem sogenannten Meinungsbild sprach sich die deutschsprachige Community mehrheitlich für diesen gravierenden Schritt aus.
Aktivismus für ein freies Internet
Der Grund: Am 26. März stand im EU-Parlament die Abstimmung über die Urheberrechtsrichtlinie an. Artikel 13 (heute 17) sollte Plattformen dazu verpflichten, Inhalte vor dem Hochladen auf Urheberrechtsverletzungen zu prüfen. Die Community der Ehrenamtlichen, Wikimedia Deutschland, zahlreiche Verbände sowie Urheberrechtsexpert*innen befürchteten: Das könnte zu massiven Einschränkungen der Meinungsfreiheit führen, da solche Prüfungen bei der Masse des täglich hochgeladenen Materials nur mit automatisierten Upload-Filtern möglich wären. Das Problem daran: Community kann Kontext, Filter nicht.
Mitarbeitende von Wikimedia Deutschland, die Rahmen der Kampagne „Community kann Kontext, Filter nicht“ beim SPD-Parteitag gegen Upload-Filter und für ein modernes Urheberrecht protestieren. Mit dabei war auch damals schon die heutige Leiterin des Teams Politik und öffentlicher Sektor, Lilli Iliev (im Vordergrund) und der damalige Justiziar von Wikimedia Deutschland, Urheberrechtsexperte John Hendrik Weitzmann (2.v.r.). Foto: Foto: Christian Schneider, No-Upload-Filter Verteilaktion (1), CC BY-SA 4.0
Mitarbeitende von Wikimedia Deutschland, die Rahmen der Kampagne „Community kann Kontext, Filter nicht“ beim SPD-Parteitag gegen Upload-Filter und für ein modernes Urheberrecht protestieren. Mit dabei war auch damals schon die heutige Leiterin des Teams Politik und öffentlicher Sektor, Lilli Iliev (im Vordergrund) und der damalige Justiziar von Wikimedia Deutschland, Urheberrechtsexperte John Hendrik Weitzmann (2.v.r.). Foto: Foto: Christian Schneider, No-Upload-Filter Verteilaktion (1), CC BY-SA 4.0
So lautete der Titel einer Kampagne, die Wikimedia Deutschland bereits 2017 gestartet hatte. Denn Filter können zwar einen Inhalt erkennen, nicht aber den Nutzungskontext korrekt bewerten. Die technologische Entwicklung war und ist nicht so weit, dass Filter zuverlässig Satire oder Parodien erkennen können. Oder – und das ist besonders für die Wikipedia relevant – ein zulässiges Zitat aus einem urheberrechtlich geschützten Text von einem Urheberrechtsverstoß unterscheiden können. Die Community und Wikimedia Deutschland sahen die freie Verbreitung von Wissen im Internet gefährdet. Die Befürchtung war, dass massenhaft rechtskonforme Inhalte in den Upload-Filtern hängen bleiben würden.
Genauer hat es John Weitzmann, damals Justiziar bei Wikimedia Deutschland, erklärt.
Wir haben daher im Rahmen unseres juristischen Diskussionsformats MonstersofLaw mit Rechtsexpert*innen und Politikschaffenden über die Risiken von Upload-Filtern gesprochen und Argumente für eine grundrechtsfreundliche Umsetzung der EU-Urheberrechtsrefom diskutiert. Mit der Kaffeefilter-Aktion beim Parteitag der SPD in Berlin am 7. Dezember 2017 haben wir Politikschaffende für die grundrechtsgefährdenden Potenziale von Upload-Filtern sensibilisiert.
Weithin sichtbar war eine Projektion, die wir am 4. April 2019 an das Bundeskanzleramt geworfen haben: Keine Uploadfilter – Stehen Sie zum Koalitionsvertrag. Denn obwohl die Koalition aus CDU/CSU und SPD im Koalitionsvertrag zugesagt hatte, Plattformen nicht zum Einsatz von Upload-Filtern zu verpflichten, hatte die Bundesregierung dem Entwurf zur EU-Urheberrechtsreform zugestimmt. Die Richtlinie der EU verpflichtet zwar nicht explizit zum Einsatz von Upload-Filtern. Die Vorgaben in Artikel 17 machten sie aber unabdingbar. Und nachdem in Brüssel die Reform des Urheberrechts beschlossen worden war, ging es um die Umsetzung in nationales Recht. In einem offenen Brief gemeinsam mit dem Digitalverband Bitkom, dem Verbraucherzentrale Bundesverband, dem Chaos Computer Club und verschiedenen Wirtschaftsverbänden haben wir die Bundesregierung dazu aufgefordert, eine zukunftsgerichtete Digital- und Urheberrechtspolitik auf nationaler Ebene zu gestalten.
Foto: http://pixelhelper.org/, Lichtprojektion ans Bundeskanzleramt – Keine Uploadfilter! Aktion von Wikimedia Deutschland 7, CC BY-SA 4.0
Foto: http://pixelhelper.org/, Lichtprojektion ans Bundeskanzleramt – Keine Uploadfilter! Aktion von Wikimedia Deutschland 7, CC BY-SA 4.0
Haben die Proteste etwas bewirkt?
Dass über 100.000 Menschen wegen eines digitalpolitischen Themas auf die Straßen gehen und über 5 Millionen Menschen eine Petition gegen Upload-Filter unterzeichneten, hatte es bis dahin noch nicht gegeben – und auch seitdem nie wieder. Und die Proteste haben Wirkung gezeigt, wie Felix Reda, Urheberrechtsexperte und von 2014 bis 2019 Mitglied des Europäischen Parlaments, beschreibt.
Die Demonstrationen und die Kritik von zivilgesellschaftlichen Institutionen haben dazu geführt, dass etwa in Deutschland die Umsetzung von Artikel 17 in nationales Recht vergleichsweise grundrechtsfreundlich erfolgt ist.
Felix Reda — Urheberrechtsexperte
Denn das deutsche Urheberrechts-Diensteanbieter-Gesetz legt fest, dass „mutmaßlich erlaubte“ Inhalte nicht automatisch gefiltert werden dürfen. Als mutmaßlich erlaubt gelten Inhalte, die weniger als die Hälfte eines fremden Werks enthalten, dieses mit anderen Inhalten verbinden oder erlaubte Nutzung enthalten – wie ein Zitat oder eine Parodie. Als mutmaßlich erlaubt gelten auch Uploads, in denen nur in geringfügigem Maß andere Inhalte genutzt werden. Geringfügig sind laut Gesetz bis zu 160 Zeichen eines Textes, 15 Sekunden von einem Video oder Musikstück und bis zu 125 Kilobyte von einem Foto, einer Grafik oder einem Bild.
Die Proteste haben auch dazu beigetragen, dass Artikel 17 im finalen Gesetzentwurf überarbeitet wurde – im Sinne der Nutzenden. Die europäischen Gesetzgeber haben den Passus ergänzt, dass legale Inhalte nicht gesperrt werden dürfen. Eine frühere Version von Artikel 17, die diese Schutzvorkehrung nicht enthielt, hatte das Europaparlament infolge der Proteste abgelehnt.
Felix Reda — Urheberrechtsexperte
Außerdem legte Polen vor dem Europäischen Gerichtshof Klage gegen Artikel 17 ein. In seinem Urteil gab das Gericht der Klage zwar nicht statt, aber:
Das Urteil des EUGH hat die Grundrechte eher gestärkt. Es hat Artikel 17 zwar nicht für unvereinbar mit Grundrechten erklärt, aber geurteilt, dass Filter nur so genutzt werden dürfen, dass sie offensichtlich illegale Inhalte sperren.
Felix Reda — Urheberrechtsexperte
Was aus den Upload-Filtern geworden ist
Wie genau große Plattformen Upload-Filter einsetzen, ist meistens nicht nachvollziehbar. Dass massenhaft Inhalte in den Filtern hängen bleiben, ist nicht zu erkennen.
Wenn man sich die Transparenzberichte von Tech-Giganten wie Meta und Co. anschaut, die diese aufgrund des DSA veröffentlichen müssen, dann sieht man: Artikel 17 ist sehr selten die Grundlage für die Sperrung von Inhalten. Die Plattformen moderieren Inhalte vor allem nach ihren Terms of Service. Wenn ein Uploadfilter eine legale Nutzung Parodie nicht erkennt, führt das seltener zu einer vollständigen Sperrung, sondern eher zur Demonetarisierung, die Werbeeinnahmen werden also der falschen Person zugeordnet. Das ist für Content Creator zwar ebenfalls ärgerlich, aber ein weniger großes Problem für die Meinungsfreiheit.
Felix Reda — Urheberrechtsexperte
Meistens entfernen Plattformbetreibende Inhalte, weil es sich um Hassrede, Bedrohungen, Betrug oder Verletzung der Privatsphäre bzw. des Datenschutzes handelt. Sperrungen aufgrund von Urherrechtsverstößen kommen vergleichsweise selten vor.
Dass die EU-Urheberrechtsreform das Internet kaputt macht, wie manche Protestierende befürchteten, ist nicht eingetreten. Das liegt auch an den vielfältigen Aktionen und Protesten. Sie haben dazu geführt, dass die Mitgliedsstaaten der EU dazu verpflichtet wurden, Schutzvorkehrungen zu treffen, damit legale Inhalte gar nicht erst gesperrt werden.
Stefan Mey präsentierte zunächst sein Buch, das die Vielfalt nicht-kommerzieller Projekte als “digitale Gegenwelt zu den kommerziellen Tech-Giganten” beschreibt. Trotz ihrer Transparenz und Nutzerorientierung bleiben diese Projekte oft hinter den Angeboten großer Konzerne zurück. Mey identifizierte fehlende finanzielle Ressourcen und stabile Infrastrukturen als Hauptprobleme. Er betonte: „Stabile Infrastrukturen wie große Rechenzentren fehlen, wodurch die alternativen Anwendungen nicht immer reibungslos laufen.“
Herausforderungen und Lösungsansätze
Die Diskussion verdeutlichte, dass staatliche Institutionen mehr tun müssen, um nicht-kommerzielle Projekte zu fördern. Katharina Nocun betonte die Bedeutung staatlicher Unterstützung für die Entwicklung gemeinnütziger Software. Tobias B. Bacherle kritisierte die komplizierten Ausschreibungsverfahren, die großen Konzernen zugutekommen. Eine Lösung könnte laut Stefan Mey in Kooperationen zwischen kleineren Unternehmen und Open-Source-Entwicklern liegen. Er fügte hinzu: „Eine weitere Möglichkeit der Finanzierung kann auch entstehen, wenn kleinere Unternehmen, die ebenfalls mit Big-Tech Konzernen hadern, Kollaborationen mit Open Source Entwicklern eingehen.“
Bewusstsein für digitale Souveränität schaffen
Es wurde diskutiert, dass fehlendes Bewusstsein für digitale Souveränität ein zentrales Problem darstellt. Die Bedeutung dieses Themas muss sowohl von Unternehmen als auch von der Bevölkerung erkannt werden. Hier besteht noch Aufklärungsbedarf, um ein Umdenken zu erreichen.
Förderung und politische Maßnahmen
Abschließend wurde betont, dass konkrete Maßnahmen und Förderungen notwendig sind, um nicht-kommerzielle Projekte zu stärken. Dies kann durch finanzielle Unterstützung, aber auch durch politisches Engagement und Sensibilisierung für digitale Souveränität geschehen. Katharina Nocun erinnerte daran: „Dass aktuell von staatlicher Seite eher kommerzielle Dienstleister genutzt werden, ist auch ein Regulierungsversagen.“
Fazit: Eine andere digitale Welt ist möglich
Die Diskussion bei Wikimedia Deutschland verdeutlichte die Herausforderungen und Chancen nicht-kommerzieller Projekte im digitalen Raum. Es liegt an allen Beteiligten, gemeinsam Lösungen zu finden und eine digitale Welt zu schaffen, die auf Prinzipien wie Transparenz, Freiheit und Selbstbestimmung basiert.
Die gesamte Podiumsdiskussion im Video:
By playing the video you agree that YouTube and Google might store and process your data. Please refer to Google’s Privacy Policy.
Mehr zu den Panelteilnehmer*innen:
Stefan Mey ist Buchautor und investigativer IT-Journalist. Er interessiert sich dafür, welche Auswirkungen digitale Umstände auf eine Gesellschaft haben und hat sich von Anfang an für die Frage von Macht und Gegenmacht im Internet interessiert. Mey kennt sowohl große IT-Konzerne als auch viele unbekannte Projekte der digitalen Gegenwelt von innen.
Katharina Nocun ist Publizistin und ehemalige Politikerin. Sie war von Mai bis November 2013 politische Geschäftsführerin der Piratenpartei Deutschland und leitete bei Campact unter anderem die Kampagne „Schutz für Edward Snowden in Deutschland“. Seit 2012 veröffentlichte Nocun vornehmlich Artikel zu digital politischen Themen und seit 2020, häufig gemeinsam mit der Sozialpsychologin Pia Lamberty, Sachbücher und Artikel zu Verschwörungstheorien und Esoterik.
Tobias B. Bacherle ist ein deutscher Politiker (Bündnis 90/Die Grünen) und seit 2021 Mitglied des Deutschen Bundestages. Für seine Fraktion ist Bacherle Mitglied im Auswärtigen Ausschuss und Ausschuss für Digitales. Bacherle ist entschiedener Gegner der sogenannten Chatkontrolle.
Moderation: Tobias Schmid ist Informations- und Kommunikationswissenschaftler und Moderator, dessen Arbeit sich darum dreht, die digitale Transformation besser zu verstehen. Als Moderator legt er Wert darauf, eine angenehme und rücksichtsvolle Atmosphäre zu schaffen, damit sich Publikum und Gäste während des Diskurses wohlfühlen.
Neue Folge von „Wissen. Macht. Gerechtigkeit.“: Wer bricht die Macht der IT-Konzerne?
Um die Frage, wem das Internet gehört, geht es auch in der aktuellen Folge des Podcasts „Wissen. Macht. Gerechtigkeit.“ in Zusammenarbeit mit dem Deutschlandfunk Kultur. Autor Stefan Mey, der Informatiker und KI-Kritiker Jürgen Geuter alias tante und die Autorin und Forscherin Zara Rahman diskutieren, wie Wikipedia, Mastodon, Firefox oder Signal das Internet fairer, freier und demokratischer machen.
Bezahltes Schreiben im PR-Auftrag in der Wikipedia, ist ein Thema, das mich und die Wikipedia-Community seit einigen Jahren umtreibt. Das Thema wabert seit etwa 2010 durch die Wikipedia, mal intensiver und mal weniger intensiv diskutiert; mal mit Skandal und mal ohne. Aber wenn man sich, ganz ohne Insiderkenntnisse, einfach mal durch Wikipedia-Artikel lebender Personen clickt (sei es in der deutschen Ausgabe oder der englischen): normalerweise riecht man die gekauften und geschönten Artikel 500 Kilobyte gegen den Wind. Die peinlichen PR-Artikel: weil auch die siebte Teilnahme am Rettet-die-Bergdackel-Benefiz-Gala-Dinner getreulich unter dem Punkt „gesellschaftliches Engagement“ gelistet wird. Die weniger peinlichen PR-Artikel: weil sie so nichtssagend sind.
Wie lange das Problem existiert und wie sehr es schon vor vielen Jahren auffiel, wurde mir letztens beim lesen gewahr. Es war ein Fantasy-Crime Roman – komplett fiktiv, mit vagen Bezugspunkten zu unserer Welt. Und selbst dort kommt Wikipedia-PR-Schreiben vor. Es geht um „Moon over Soho“ von Ben Aaronovitch. Erstmal erschienen 2012 bringt es der Roman auf den Punkt:
Auf deutsch etwa:
„Die Reichen, vorausgesetzt sie vermeiden Prominenz, können etwas Unternehmen um ihre Anonymität zu bewahren. Lady Tys Wikipedia-Artikel las sich als wäre sie von einem PR-Schreiber verfasst worden, denn zweifellos hatte Lady Ty einen PR-Schreiber beschäftigt, um sicherzustellen, dass die Seite ihren Vorstellungen entsprach. Oder wahrscheinlicher: Einer ihrer „Leute“ hatte eine PR-Agentur beauftragt, die einen Freelancer beschäftigt hatte, der das in einer halben Stunde runtergeschrieben hatte, damit er sich schneller wieder auf den Roman konzentrieren konnte, den er grade schrieb. Der Artikel gab preis, dass Lady Ty verheiratet war, zu nicht weniger als einem Bauingenieur, dass sie zwei schöne Kinder hatten von denen der Junge 18 Jahre alt war. Alt genug um Auto zu fahren aber jung genug um noch zu Hause zu wohnen.“
Diese Beschreibung trifft auch zehn Jahre später auf einen Großteil aller PR-Artikel zu. Schnell und lieblos, aber professionell gemacht. Oft genug mit Versatzstücken aus anderen Werbematerialien; zu unauffällig, um jemand ernstlich zu stören. Aber auch zu nichtssagend, um der Leser*in auch nur den geringsten Mehrwert zu bieten.
Damit hat ein Roman-Autor, der selber kein aktives Mitglied der Wikipedia-Community ist, die PR-Problematik schon im Jahr 2012 richtiger eingeschätzt als ein relevanter Teil der diskutierenden Community im Jahr 2022.
(Und Randbemerkung: die Community rächte sich, indem sie Aaronovitchs Autoren-Artikel mit einem unvorteilhaften Autorenfoto versah – no PR-flack weit und breit war hier unterwegs.)
Von einer anderen Form des beeinflussten Schreibens erfuhr ich heute beim Mittagsessen. In immer mehr autoritären Regimes scheint es vorzukommen, dass einzelne Wikipedia-Autor*innen, die in dem jeweiligen Land leben, einen Anruf oder einen Besuch bekommen. Mit dem freundlichen Tipp, doch den ein oder anderen Artikel zu „verbessern“ sonst.. Das ist natürlich noch raffinierter: Einfach einen etablierten Nutzer und dessen Vertrauensvorschuss nehmen und in dieser Tarnung PR-Edits durchführen.
Menschen können auf der Wikipedia:Auskunft Fragen an die Wikipedia richten. Die Fragen sind mal banal, mal lehrreich, und manchmal hohe Poesie. Daran solltet ihr teilhaben.
Ich stelle mich auf, Brust nach vorne, Kinn nach oben, räuspere mich noch einmal und deklamiere:
Wir waren dieses Jahr mit WikiAhoi wieder bei der SMWCon dabei. Die Konferenz zu Semantic MediaWiki findet zweimal pro Jahr statt, im Frühling in Nordamerika und im Herbst in Europa. Letztes Jahr waren wir schon in Wien dabei und dieses Jahr gings ins herbstlich-sonnige Barcelona. In freundlicher, persönlicher Atmosphäre wurden technische Neuigkeiten, innovative Projekte und besondere Anwendungsfälle besprochen. Wir möchten Sie an den wichtigsten Neuerungen teilhaben lassen.
Neuigkeiten aus der Semantic MediaWiki-Welt
Semantic Forms (Version 3.4 September 2015) hat sich mittlerweile als eigenständige Erweiterung etabliert und ist nun technisch nicht mehr von der Grunderweiterung Semantic MediaWiki abhängig. Weitere wichtige Änderungen:
Statt den Spezialattributen werden nun ParserFunctions eingesetzt.
Kartenbasierte Eingabeformate (Google Maps, Open Layers) sind nun möglich – diese werden nur eingesetzt, wenn Semantic Maps nicht vorhanden ist.
Weiters wird nun Cargo unterstützt, es lassen sich in Formularen auch Eingabeformate und die Autovervollständigungsfunktion aus Cargo nutzen.
Dazu kann man nun auch „mapping“-Werte hinterlegen, das sind andere Werte, als auf der Seite angezeigt werden.
Ein neuer Parameter erlaubt es, nur einzigartige Werte speichern zu lassen.
Alle roten Links können nun mit einer einzelnen Einstellung auf eine Formularauswahlliste weitergeleitet werden.
Die MediaWiki Stakeholder’s Group nahm die Konferenz zum Anlass, um weitere Schritte zu besprechen: Ziel der Gruppe ist die Koordination und die Kommunikation mit Wiki-Nutzern in Unternehmen, die Unterstützung von Entwicklern und Administratoren und die offizielle Kommunikation mit der Wikimedia Foundation. Wikipedia hat etwas andere Ziele als einzelne Drittnutzer der Software MediaWiki. Es geht also stark darum, die Interessen der Nutzer von Wiki in Unternehmen zu vertreten und in der Weiterentwicklung der Software voranzutreiben.
Interessante neue semantischeErweiterungen gibt es zu Breadcrumbs, Zitaten, Sprachenlinks und Metatags:
Semantic Breadcrumb Links – mittels Attributen können Breadcrumbs erstellt werden, die eine Hierarchie erzeugen, ohne Unterseiten erstellen zu müssen.
Semantic Cite – unabhängig von der Cite Erweiterung, ermöglicht das seitenübergreifende Verwenden von Zitaten und eine automatische/manuelle Quellenliste.
Semantic Interlanguage Links – automatische Sprachanzeigen (gibt es diese Seite in anderen Sprachen?) in Wikis mit Interwikis.
Und warum „eine Konferenz mit Folgen“? Diese Konferenz hat Folgen auf mehreren Ebenen: Wir haben persönliche Kontakte für Zusammenarbeit und Austausch geknüpft, es wurden Ideen beflügelt und Inspirationen für neue Projekte ausgetauscht, die Motivation wieder gestärkt, das Projekt MediaWiki als Ganzes voranzubringen und nicht zuletzt viele Features und Software-Änderungen besprochen, die in der Regel meist recht schnell umgesetzt werden. Die Konferenz war somit ein voller Erfolg.
Die Konferenz fand von 28.–30.10.2015 in Barcelona statt, in der schönen Fabra i Coats Kunstfabrik im Stadtteil Sant Andreu. Knappe 40 Teilnehmer nahmen an einem Tutorial- und zwei Konferenztagen teil.
Die deutschsprachige Wikipedia-Community versucht wieder einmal, die Regeln zum bezahlten Schreiben zu verschärfen. Das Thema wabert ungelöst seit Jahren durch das Wikiversum. Und auch dieses Meinungsbild ist ein notwendiger Schritt voran. Aber der Weg ist noch weit. Der beste Kommentar meinerseits wäre die Komposition eines Quartetts für Singende Säge, Bassdrum, Cembalo und Spottdrossel.
Aber ich kann nicht komponieren. Deshalb kommt das Nächstbeste: ein Gedicht.
Wikipredia
Die Regeln existieren und doch nicht nach Mondstand
Die Ethik absolut seit Anbeginn nein denn ja
Die Praxis gesperrt verworfen gelöscht freigeschaltet
Wikipredia Darwinismus der Agenturen Überleben des Dreistesten
Darmstädter Madonna
Hans Holbein der Jüngere, 1526/1528
Öl auf Nadelholz (?), 146,5 × 102 cm
Sammlung Würth, Johanniterhalle (Schwäbisch Hall)
Wikipedia-KNORKEerwähnte ich ja an dieser Stelle schon einmal. Berliner Wikipedianerinnen und Wikipedianer treffen sich und erkunden zusammen eine ihnen unbekannte Gegend. Soweit so üblich. Diesmal jedoch gab es etwas besonderes: Auf ins Museum!
In Berlin gastiert gerade die Darmstädter Madonna, ein 1526 entstandenes Gemälde von Hans Holbeim dem Jüngeren. Diese Madonna hat eine bewegte Lebens- und Reisegeschichte, ist eines der bedeutendsten deutschen Gemälde des 16. Jahrhunderts und kann Menschen auch über Jahre faszinieren. Wunderbar, wenn man eine kundige Bilderklärung der Autorin des exzellenten Wikipedia-Artikels dazu bekommt.
Wir trafen uns einige Minuten vor der Öffnung in kleiner Gruppe vor dem Bode-Museum und konnten - da alle Anwesenden über eine Jahreskarte verfügten - auch sofort zur Madonna und zur Sonderausstellung "Holbein in Berlin" begeben. Der Raum war noch leer, die Museumswachmannschaft ließ freundlicherweise die leise aber engagiert redende Gruppe gewähren. Ein einziger Saal, in dessen Mittelpunkt die Madonna hängt. Links davon einige Holbein-Teppiche, ansonsten weitere Bilder und Zeichnungen von Holbein, Inspiratoren und andere Madonnen. Nicht überladen, sinnvoll aufbereitet und mit einem klaren Konzept - eine der besseren Kunstausstellungen.
Und dann ging es los: Es begann mit Schilderungen von der bewegten Entstehungszeit zur Zeit des Basler Bildersturms im Auftrag des Basler Ex-Bürgermeisters Jakob Meyer zum Hasen. Die Aussage des Bildes traditioneller Marienfrömmigkeit in Zeiten der Reformation war Thema, ebenso natürlich wie der Teppich und seine Falte. Wir staunten über die Eigentümlichkeit, dass sich niemand auf dem Gemälde eigentlich anschaut und wurden über dden Unterschied zwischen Schutzmantelmadonnen und Stifterbildern aufgeklärt. Vermutungen tauchten auf, wo das Bild wohl im Original hing - vermutlich in der Martinskirche als Epitaph - und wir verfolgten gedanklich seine Wanderung aus Basel über den Grünen Salon im Berliner Stadtschloss bis hin zum Hause Hessen und das Frankfurter Städelmuseum bis hin zum spektakulären Verkauf an die Privatsammlung Würth. Die Meinungen über die Sammlung Würth in der Gruppe waren durchaus geteilt, ebenso wie die richtige Benennung des Bildes: ist es nun eher die Darmstädter Madonna oder eher die Madonna des Bürgermeisters Jakob Meyer zum Hasen?
Über die Darmstädter Madonna ging es dann zur Dresdner Madonna und einem der prägenden Momente deutscher Kunstgeschichte: dem Dresdner Holbeinstreit. Im 19. Jahrhundert wurde es den Menschen bewusst, dass es zwei fast identische Holbein-Madonnas gab und nur eine die echte sein konnte. In einer großen Ausstellung, unter lebhafter Anteilnahme der Öffentlichkeit und erregten Debatten der Experten entschieden sich die Kunsthistoriker schließlich für das Darmstädter Gemälde. Eine Sensation, da die Kunstkennerschaft vorher felsenhaft von der Originalität des Dresdner Gemäldes ausging. Hier zeigte sich erstmals das Bemühen, um eine rein sachlich, objektive Abwägung der verschiedenen Gesichtspunkte - der Dresdner Holbeinstreit ist einer der Ausgangspunkte um die Kunstwissenschaft als Wissenschaft zu etablieren. Und - wie sich später herausstellte - lag die Kunstwissenschaft auch in diesem ihren Anfangsurteil richtig; sämtliche mittlerweile vorhandenen naturwissenschaften Verfahren die Darmstädter Madonna als die originale der beiden bestätigten.
Erkenntnisse am Rande: eine weitere Kopie des Gemäldes (beziehungsweise eine Kopie der Kopie - es stellt aus unerfindlichen Gründen das Dresdner Exemplar dar) hat sich in das Set des James-Bond-Filmes "Man lebt nur zweimal verirrt".
Hans Holbein der Jüngere: Bildnis des Danziger Hansekaufmanns Georg Gisze in London, 1532. Eichenholz, 96,3 × 85,7 cm. Gemäldegalerie Dahlem der Staatlichen Museen zu Berlin – Preussischer Kulturbesitz
Und nachdem wir dann auch noch gerätselt hatten, wer die beiden Knaben unterhalb der Madonna sind, den verschwundenen Haaren der Tochter nachspürten und weiter über den Teppich in der Renaissancemalerei sinniert hatten, kamen wir dann nach knapp einer Stunde noch zu Georg Giesze. Giesze (auch Georg Giese) ist Titelheld in einem anderen Holein-Hauptwerk, das praktischerweise fünf Meter weiter links hing. Wieder mit Teppich und nun auch noch mit Glas, Metall, Bücherregalen und Briefen. Gedanklich begleitete wir Holbein dann weiter von Basel nach Antwerpen und London. Mittlerweile hatte sich der Raum etwas gefüllt. Nachdem wir dann noch den Weg aus dem Museum gefunden hatte (wie immer im Bodemuseum nicht ganz einfach und jedes mal findet man zwischendurch neue Säle) folgte noch ein erschöpfter Abschlusskaffee.
Eine Stunde fast allein mit der Madonna. Und immer noch Neues zu entdecken.
Über den Dächern, Türmen und Gasometern Westberlins senkte sich die Abendsonne. Ich stand auf den Zinnen des Ullstein Castles und sinnierte. Direkt unter mir Straßentreiben, Sirenen, betrunkene Jugendliche, ein Ausflugsboot auf dem Teltowkanal, radelnde Ausflügler überquerten die Stubenrauchbrücke.
In der Ferne betrachtete ich die Türme des Spitzenlastheizkraftwerks Lichterfelde, der Sendeturm auf der Marienhöhe, den BfA-Büroturm und den ehemaligen Wasserturm im Naturpark Schöneberger Südgelände. Heute Nacht auf dem Heinweg: Welchen Weg sollte ich wählen? Unten, im Süden, über den Prellerweg vorbei am Sommerbad am Insulaner? Die Nordvariante über den Tempelhofer Damm und durch die Kopfsteinpflaster Tempelhofs? Oder die Mittelweg, mit Erklimmen der Höhe am Attilaplatz und später über den Ikea-Parkplatz? So viel zu wählen.
Wahlen spukten in meinem Kopf herum. Da war die Mitgliedsversammlung unseres Dauergartenvereins. Die Vorstandswahlen dort sollten wahrscheinlich, hoffentlich, unspektakulär verloren. Aber die Anträge. Wenn ein einzelnes Mitglied auf einem A4-Blatt 40 verschiedene Anträge stellt, richtig ernsthaft, dann verspricht das Unterhaltung.
Die Bundestagswahl: Auf dem Weg zum Ullstein Castle passierte ich zahlreiche Bundestagstagswahlplakate: den unlesbaren Blob der Grünen in Tarnfarbenoliv, die bildhaft dargestellte Biederkeit der Berliner SPD, zahlreiche Kleinparteien von Team Tödenhöfer über Volt bis zur Tierschutzpartei. Und so sehr es mich schmerzte das zu sagen: Das Plakatgame gewannen bisher die CDU und ihr Wahlkreiskandidat Jan-Marco Luczak. Sowohl optisch – als auch damit, überhaupt inhaltliche Aussagen fern von Plattitüden zu machen.
Vor allem aber war ich innerlich bei einer ganz anderen Wahl. Die Wikimedia Foundation wählte und wählt ihr Board, auf Deutsch das ehrenamtliche Präsidium der Wikimedia Stiftung. Die Wikipedia steht meinem Herzen näher als der Bundestag und selbst als der Dauergartenverein. Aber die Board-Wahlen erfordern merh Gedanken. Diese Gedanken bedurften des Kontextes.
Was ist die Wikimedia Foundation?
Die Wikimedia Foundation (WMF) ist die Betreiberin der Wikimedia-Projekte wie zum Beispiel der Wikipedia aber auch Wikimedia Commons und Wikidata. Die Foundation hostet die Server, stellt die Technik, ist am Ende rechtlich dafür verantwortlich was in den Wikipedien passiert. Dafür hat die Foundation derzeit etwa 450 Angestellte, ein Endowment von 90 Millionen Dollar und hatte 2020 Jahreseinnahmen von 127 Millionen US-Dollar.
Wo genau die Grenzen zwischen dem Einfluss der Wikimedia Foundation und den Communities liegen, ist umstritten. Letztlich kann die Foundation alles ändern und machen in den Projekten. Sie ist meistens weise genug, es nicht zu tun. Insbesondere schreiben keine Foundation-Mitarbeiter*innen in ihrer Arbeitszeit Artikel oder legen Inhalte in den Projekten an.
Die Foundation ist eine Organisation eigener selbstgenügsamer Vollkommenheit. Sie hat keine Mitglieder und ist – rechtlich – niemand rechenschaftspflichtig. Das Board besetzt sich prinzipiell aus sich selbst heraus. Es hat entschieden die Hälfte der Sitze Wahlen der weltweiten Wikip/media-Communities besetzen zu lassen zu lassen.
Das Board of Trustees ist das ehrenamtliche Aufsichtsgremium der Foundation. Es hat derzeit 16 Sitze. Davon steht einer Jimmy Wales als Gründer zu, sieben Sitze besetzt das Board selber, acht Sitze werden durch eine weltweite Communitywahl bestimmt.
Nun ist allein aus den Worten „ehrenamtlich“ und „weltweit / 450 Mitarbeiter / 127 Millionen Dollar Einnahmen“ klar, dass das Board eine abstrakte Leitungsposition einnimmt. Alleine, einen Überblick über so eine Organisation zu behalten, ist eine Mammutaufgabe. Dieser Organisation noch Vorgaben zu machen und sie in eine bestimmte Richtung zu lenken, eine Herausforderung.
Die Gefahr, in Detailinformationen zu ertrinken oder sich hoffnungslos im Alltagsgeschäft zu verfangen, ist groß. Seiner Aufgabe nach, beaufsichtigt das Board, was die Vollzeitkräfte machen und besetzt die Geschäftsführung.
Was zur Zeit ein besonderer Job ist: Die Geschäftsführerin der Foundation Catherine Maher verschwand im April 2021 überraschend. Der Posten ist seitdem unbesetzt. Ebenso wie sich die Chief Operations Officer im Jahr 2021 verabschiedete, die Abteilungen Communication und Technology auch niemand im Vorstand haben. Auf dem Schiff besetzt nur eine Notbesatzung an Offizier*innen die Brücke. Dem Board obliegt es derzeit, dieses Führungsvakuum schnell und kompetent zu beenden.
Grundsätzlich sollte jede*r Kandidat*in zwei Kriterien erfüllen. Sie sollte meine inhaltlichen Ziele teilen. Und sie sollte in der Lage sein, sich in einem ehrenamtlichen Job gegen eine komplette Organisation aus Vollzeitangestellten zu behaupten. Oft genug stehen bei solch ehrenamtlichen Gremien Kandidat*nnen zur Wahl, bei denen ich denke „Will Schlechtes, aber wird das erreichen“ und „Will Gutes, ist aber planlos. Am Ende werden die Hauptberuflichen machen was sie wollen. Oder es gibt Chaos.“
Angesichts der bewegten Zeiten, in denen wir leben; angesichts der latenten Führungslosigkeit der Foundation derzeit, möchte ich Kandidat*innen, die sich durchsetzen können. Kandidat*innen, die nach Möglichkeit die US-Zentrik der Foundation aufbrechen können. Ich möchte Kandidat*innen, die verstehen, dass Wikip/media keine allgemeine Weltbeglückungsorganisation ist, sondern sehr spezifische Sachen sehr gut durchführt – und andere überhaupt nicht kann. Es bringt nichts, sich auf allgemeine Weltbeglückungsziele zu stürzen, die weder die Foundation noch die Communities umsetzen können.
Insgesamt stehen 19 Kandidat*innen zur Auswahl, die um vier Plätze streiten. Dabei sind Wikimedia-Urgesteine ebenso wie Newbies, viele Männer, mir auffallend viele Inder, viele Kandidat*innen mit NGO-Hintergrund, kaum eine*r, der/die fortgeschrittene IT-Kenntnisse hat.
Die Urgesteine
Dariusz Jemielniak – Professor of Management, daueraktiv auf allen Ebenen und vielleicht der einzige Mensch, der intellektuell versteht wie Wikipedia funktioniert.
Rosie Stephenson-Goodknight – WikiWomensGroup, Women in red, you name it. Bei überraschend vielen der Wikipmedia-Genderaktivitäten, die funktionieren, ist Rosie Stephenson-Goodknight beteiligt.
Gerard Meijssen – gefühlt war Gerard schon Wikipedianer bevor es Wikipedia gab. Vielleicht der spannendste Autor des Meta-Wikiversums und ein Chaot.
Mike Peel – langjähriges Mitglied des Funds Dissemantion Committees. (FDC) Hat bei mir in der Rolle durchgehend einen schlechten Eindruck hinterlassen.
Ravishankar Ayyakkannu – Mr. Tamil Wikipedia, der seinem Resumee zufolge seit 2005 in der Community und mit externen Partnern (wie Wikipedia Zero, Google) zusammenarbeitete. Gewinnt bei mir Diversitätspunkte, weil er nicht nur aus dem Global South stammt, sondern auch Ausbildung und Berufstätigkeit dort durchführte.
Lorenzo Losa – Ex-Vorsitzender von Wikimedia Italia.
Farah Jack Mustaklem – Software Engineer, einer der wenigen Kandidaten mit Ahnung von Software. Aktiv bei den Wikimedians of the Levant und der Arabic language User Group. Mir persönlich zu sehr USA-sozialisiert für eine Board-Mitgliedschaft, andererseits sicher in jeder Hinsicht kompetent.
Douglas Ian Scott – Präsident von Wikimedia South Africa, Organisator der Wikimania 2018 und einziger Kandidat, den ich dank eines langen Wartepause am Kofferband irgendeines Wikimania-Flughafens persönlich besser kennenlernte – und begeistert war.
Iván Martínez – langjährig engagiert bei Wikimedia Mexiko, LGBTQ+-Aktivist und soweit ich hörte, das Wikiversum Lateinamerika ist begeistert von ihm.
Pavan Santhosh Surampudi – Community Manager at Quora. Versteht also vermutlich professionell etwas von Communities.
Adam Wight – Programmierer, Ex-Angestellter und WMF und WMDE und neben Gerard der Vertreter des Ur-basisdemokratischen, selbstorganisierten und Gegen-Informationsmonopole-Geistes des frühen Movements.
Vinicius Siqueira – in Wiki Movimento Brasil
Newbies
Es kann sich hierbei um langjährige und erfahrene Wikipedianer*innen handeln, die im kleinen Rahmen auch Projekte oder Gruppen organisiert haben. Erfahrungen in oder mit größeren Organisationen im Wikiversum fehlt vollkommen.
Lionel Scheepmans
Pascale Camus-Walter
Raavi Mohanty
Victoria Doronina
Eliane Dominique Yao
Ashwin Baindur
Wen werde ich wählen?
Leute, die sich durchsetzen können, und die auch die Grenzen des Wikiversums sinnvoll einschätzen können. Perspektiven auf das Leben, anders aussehen als „in US-NGOs sozialisiert“ werden bevorzugt.
Die Top 4
Douglas Ian Scott
Iván Martínez
Adam Wight
Dariusz Jemielniak
Top 8
Rosie Stephenson-Goodknight
Lorenzo Losa
Farah Jack Mustaklem
Gerard Meijssen
Wählbar
Reda Kerbouche
Pavan Santhosh Surampudi
Ravishankar Ayyakkannu
Wer wird wählen
Es wählen alle Menschen, die vage aktive Accounts in einem Wikimedia-Projekt haben. Die Bedingungen dafür sind niedrig angesetzt. Für Autor*innen ist es nötig 300 Bearbeitungen zu haben, kein Bot zu sein und höchstens in einem Projekt gesperrt zu sein. Die Bedingungen für die Board-Wahlen sind somit einfacher zu erfüllen als die Bedingungen zum Sichten in der deutschen Wikipedia. Die Kriterien mussten am 5. Juli 2021 erfüllt sein. Es hilft nicht, jetzt noch schnell zu editieren.
Das Wahlsystem
Es gilt das Präferenzwahlsystem. Dieses wird weltweit von einschlägigen Fachleuten als besonders fair bezeichnet. Es verzerrt den Wählerwillen weniger als viele andere Wahlsysteme. Praktisch wird es allerdings nur selten eingesetzt. Die bekannteste Wahl mit Präferenzwahl in letzter Zeit war die Bürgermeister*in-Wahl in New York, New York.
Bei Wahlsystem nummeriert man „seine“ Kandidat*nnen nach Präferenzen. Die beste Kandidatin bekommt eine Eins, der Kandidat danach eine zwei und so weiter. Hält man keine Kandidatin mehr für geeignet, hört man auf zu nummerieren.
Bei der Wahl werden in der ersten Runde alle Präferenzen mit „1“ gezählt. Ein Kandidat hat am wenigsten davon. Dieser scheidet aus. Von allen „1“-Wählerinnen des Kandidaten werden nun die „2“-Präferenzen seiner Wählerinnen auf die entsprechenden weiteren Kandidaten verteilt. Und so weiter, bis nur noch so viele Kandidatinnen übrig sind, wie es Plätze zu besetzen gilt.
Im ICE ist Deutschland. Der Zug fährt ein und hält. Das Schild am Gleis behauptet tapfer „Zugdurchfahrt“. Die Türen lassen sich öffnen. Am Zug steht nichts geschrieben, außer Wagennummern, die nicht zu den Reservierungen passen. Das Publikum bleibt irritiert. Etwa die Hälfte der Anwesenden geht in den Zug und bleibt im Wageninnern ratlos stehen. Die andere Hälfte steht ratlos am Bahnsteig.
Schließlich: Lichter gehen an. Der Zug verkündet mittels seiner Anzeigen nun auch, nach Kassel zu fahren. Eine Frau entschuldigt sich über die Lautsprecheranlage über die falschen Wagennummern, man solle ich immer zehn wegdenken „Also 22 statt der angezeigten 32.“
Ein Mensch mit re:publica-Bändchen am Arm verscheucht die ältere Dame ohne Reservierung von seinem Platz und liest den gedruckten Spiegel. Ich höre ein angeregtes Gespräch zwischen einem Musicaldarsteller und einer Abteilungsleiterin im Innenministerium, die sich gerade kennenlernen über, den relativen Wert von Musikgymnasien in Berlin. Geht es noch deutscher?
Illustration aus dem Buch ""Le tour du monde en quatre-vingts jours" Alphonse de Neuville & Léon Benett
Passenderweise habe ich ein entsprechendes Buch mitgenommen. Nils Minkmars „Mit dem Kopf durch die Welt.“ Das hat schon auf dem Cover ein ICE-Fenster und geht der Frage nach, was Deutschland bewegt. Minkmar lässt sich über deutsche Normalität aus. Der deutsche Ingenieur, lange Jahrzehnte Sinnbild der Normalität, sei nicht mehr normal. Minkmar erzählt aus seiner französisch-deutschen Kindheit:
„Meine Mutter nannte dann immer eine Berufsgruppe, die uns besonders fern war, nämlich les ingenieurs. Wir waren in Deutschland […] und das ganze frisch aufgebaute Land ruhte auf Säulen, die les ingenieurs berechnet, gegossen und zum Schluss noch festgedübelt hatten. […] Viele Jahre später sollte ich die Gelegenheit haben, diese seltene Spezies besser studieren zu können. Sie saßen direkt hinter mir, zwei ausgewachsene Exemplare: Ingenieure, Familienväter, auf der Rückfahrt von einer Dienstreise. Sie plauderten über die sich verändernden Zeiten. […] Fernsehen, Marken, Politiker, auf keinem Gebiet fanden sich diese beiden braven Männer wieder, alles zu grell und bunt, zu aufgeregt. Ihre spezifischen Werte und Tugenden, Sorgfalt und diese stille Freude an der eigenen Biederkeit, das alles war an den Rand gerückt. Ingenieure waren nun Exzentriker. […] Diese Männer fanden sich kulturell kaum zurecht.“
Wenn „der deutsche Ingenieur“ nicht mehr normal in Deutschland ist, sind es jetzt Ministerialbeamtinnen und Musicaldarsteller?
Forschung Maschinenbau Braunschweig
Minkmar war noch nicht in Braunschweig. Oder Braunschweig ist nicht normal. Da steige ich harmlos aus dem Zug und die Stadt schlägt mir „Deutscher Ingenieur“ rechts und links um die Ohren. Braunschweig hebt das Thema "autogerechte Stadt" in Höhen, die selbst mir als gebürtigem Hannoveraner unerreichbar schienen.
Braunschweig. Bahnhofsvorplatz.
VW ist daran beteiligt, ist klar in der Gegend. Aber nicht nur. Ich wandelte also Freitagabend gegen 21 Uhr auf der Suche nach einem Wegbier durch das verlassene Braunschweig, passierte die Stadthalle und wurde prompt begrüßt mit „Tag des Maschinenbaus. Herzlich Willkommen.“
Vor allem aber fiel mir bei diesem Wandeln auf, wie unglaublich gepflegt diese Stadt aussieht. Ich erblickte keine einzige Kippe auf dem Weg. Selbst die Großbaustelle, über die irrte, wirkte irgendwie aufgeräumt. Viel verwunderlicher war, dass selbst die in Braunschweig reichlich vorhandenen 1970er-Großbauten gepflegt und sorgsam hergerichtet wirkten. Die Stadthalle selber, offensichtlicher spät 1960er/früh 1970er-Stil wirkte besser gepflegt als Berliner Gebäude nach zwei Jahren. Die Wege und Lampen darum herum: offensichtlich keine zehn Jahre alt. Sie wirkten wie frisch aus der Packung genommen.
Wegbier. In Braunschweig nur schwerlich aufzutreiben, dann aber stilgerecht,
Selbst die Schwimmbäder sind alle gepflegt(*), alle haben gleichzeitig geöffnet und keines ist aus obskuren Gründen gesperrt. Da spielt nicht nur bürgerschaftliches Engagement eine Rolle, sondern offensichtlich ist auch Geld vorhanden.
Auf dem Hotelzimmer, noch so ein sehr gut gepflegter und hergerichteter Bau, der einem „1970er!“ ästhetisch schon ins Gesicht schreit, mit dem Hotel-Wlan (7 Tage, 7 Geräte) nachlesend, wie das nun ist mit Braunschweig. Bekanntes taucht beim Nachlesen auf: Die physikalische-technische Bundesanstalt mit der Atomuhr; geahntes lese ich (Volkswagen – hey, das ist Niedersachsen und die Technische Universität existiert ja auch) und nicht bekanntes:
„Im gesamten Europäischen Wirtschaftsraum (EWR) verfügt die Region Braunschweig über die höchste Wissenschaftlerdichte,[103] im bundesweiten Vergleich über eine hohe Ingenieurquote[104] sowie über die höchste Intensität auf dem Gebiet der Ausgaben für Forschung und Entwicklung. In der Region Braunschweig arbeiten und forschen mehr als 16.000 Menschen aus über 80 Ländern[105] in 27 Forschungseinrichtungen sowie 20.000 Beschäftigte in 250 Unternehmen der Hochtechnologie[106]“
Dazu noch „Braunschweig ist die Stadt mit der niedrigsten Verschuldung Deutschlands.“ Und nach einer obskuren EU-Rangliste ist Braunschweig die innovationsfreudigste Region der EU vor Westschweden und Stuttgart. Hier lebt der deutsche Ingenieur. Hier lebt die deutsche Technik. Was für ein passender Ort für Jules Verne.
Jules Verne
Jules Verne; französischer Erfolgsautor des 19. Jahrhunderts und vor allem bekannt als "Vater der Science Fiction." Von seinem vielfältigen Werk sind vor allem die Abenteuer-Techno-Knaller wie Zwanzigtausend Meilen unter dem Meer, die Reise Von der Erde zum Mond oder die Reise zum Mittelpunkt der Erde bekannt. Wikipedia und die Deutsche Jules-Verne-Gesellschaft hatten ein gemeinsames Wochenende organisiert mit einer Tagung zu Jules Verne und Gesprächen zu Wikipedia.
Volker Dehs bestreitet das halbe Programm
Jules Verne, mir vor allem bekannt durch vage Erinnerungen an den 1954er Nemo-Film, Weiß-orange Taschenbücher und einen blau eingebunden Robur-Roman, der mich verstörte, weil er so anders war als die großen mir bekannten Abenteuerromane von Jules Verne. Warum ich überhaupt fuhr: Intuition. Ich hätte nur schwerlich begründen können, was genau mich reizte, aber die Mischung aus Vertrauen in die Veranstalter, Science Fiction und Neugier auf diese andere niedersächsische Stadt nach Hannover, trieben mich dorthin.
Verne selber gilt als Begründer Science Fiction. Und so bringt er als Autor frankophile Literaten und Groschenromanfans, Ingenieure und Naturwissenschaftler zusammen. Besessene Bibliographen waren Thema und Anwesend, ebenso wie die phantastische Bibliothek in Wetzlar – die Mischung der Jules-Verne-Aktiven unterscheidet sich gar nicht so sehr von der Mischung der Wikipedia-Aktiven. Die Perspektiven, aus denen Verne hier unter die Lupe genommen wurden, waren vielgestaltiger als sie es in der Literatur sonst sind. Faszinierend hier war die Neigung unterschiedlicher und leicht besessener Menschen sich zu einem Thema auseinanderzusetzen.
Haus der Braunschweigischen Stiftungen - Veranstaltungsort.
Dementsprechend hatte der Veranstalter, der Wikipedia-Autor Brunswyk das Programm gestaltet: ist Verne eher katholisch oder eher laizistisch? Kam der Wille zur Aufklärung in seinen Büchern durch seinen Verleger Pierre-Jules Hetzel hinein, während auf Verne eher zurückgeht, dass alles menschliche Streben gegenüber der göttlichen Macht sinnlos bleibt? Wen inspirierte er? Ist es eine sinnvolle Frage, dem nachzugehen, welche seiner Voraussagen, sich bewahrheiten? Dazu kamen dann noch Exkursionen zu Friedrich Gerstäcker, Fenimore Cooper, die Ingenieure, die ihre U-Boote dann nach Jules Verne „Nautilus“ nannten – und stark von diesem beeinflusst waren
Für mich brachte das Treffen interessante Erkenntnisse, wie die Tatsache, dass Verne immer Theaterautor oder – produzent werden wollte und wie sehr der Katholizismus sein Denken beeinflusste. Romancier war er eher gezwungenermaßen – und verdiente mit seinen zwei erfolgreichen Theaterstücken in seinem Leben ein Viertel so viel Geld wie mit etwa 80 bis 100 Romanen.
Interessant das Rätseln aller Anwesenden, warum Vernes Roman "der Grüne Strahl" so ein kommerzieller Erfolg war, was niemand der Anwesenden nachvollziehen konnte. Und dann eine Dreiviertelstunde später kam die Bemerkung in einem anderen Zusammenhang, dass "der Grüne Strahl" quasi Vernes einziges Buch mit einer weiblichen Hauptfigur war. Ich ahne einen Zusammenhang,Update: Es kam wie es kommen musst. Da denke ich mal, ich habe etwas entdeckt, dabei habe ich nur etwas falsch verstanden. Tatsächlich ist Der Grüne Strahl nicht das einzige Werk mit einer Protagonistin. Das prägnanteste Buch ist dabei Mistress Branican*, da hier die Titelfigur die komplette Handlung quasi im Alleingang bestreitet. Aber auch in anderen Büchern spielen Frauen eine wichtige Rolle (und dieser Umstand war Jules Verne sogar so wichtig, dass er in Interviews darauf hinwies): Die Kinder des Kapitän Grant*, Nord gegen Süd*, Reise um die Erde in 80 Tagen*, Ein Lotterielos* ... und einige mehr. (*Affiliate Links)
Für mich neu war die Erkenntnis, dass ein Großteil von Vernes Werk gar nicht in den Bereich Science Fiction gehört, sondern es (fiktive) Reisebeschreibungen sind. Und selbst dort wo Verne Maschinen und phantastische Gerätschaften erfindet, dienen diese vor allem dem Zweck zu reisen.
Und jetzt recherchiere ich, natürlich, zum Grünen Strahl.
Die Phantastische Bibliothek
Meine beiden Programmhighlights beschäftigten sich nur mittelbar mit Jules Verne. Sie kamen von der Phantastischen Bibliothek Wetzlar: zum einen der Rückblick von Thomas Le Blanc auf Wolfgang Thadewald. Den großen Phantastik- und Jules-Verne-Sammler. Thadewald verstarb 2014. Er lebte in Langenhagen. Mehrere der Anwesenden hatten ihn noch persönlich gekannt. Und die Schilderung seiner Sammlertätigkeit, seiner Liebe zu Büchern und zu Menschen, aber auch die Besessenheit mit der Thadewald an ein Thema heranging und auch von Krankheit schon schwer gekennzeichnet das Arbeiten an Bibliographien nicht lassen konnte – es ließ sich nicht anders beschreiben als bewegend. Sicher war dieser Vortrag mein emotionaler Vortrag des Programms.
Wer auch immer aber auf die Idee kam, den Vortrag von Klaudia Seibel zu Future Life: Wie (nicht nur) Jules Verne dabei hilft, die Zukunft zu gestalten an Ende der Konferenz zu legen: Chapeau! Das Projekt ist, kurz gesagt, ein Projekt der Phantastischen Bibliothek. Die stellt zu bestimmten Themen Dossiers zusammen, wie Science-Fiction-Autoren sie sich vorstellen. Die Berichte werden manchmal von öffentlichen Stellen, öfter von Großunternehmen bestellt, die damit selber zukunftsfähig werden wollen und in die Zukunft denken.
Wobei Auftraggeber von Staats wegen selten sind. Die meisten Aufträge kommen aus der Privatwirtschaft. Die allerdings meist gleich umfangreiche Verschwiegenheitsklauseln verlangt, weshalb die Phantastische Bibliothek da wenig zu sagen kann.
Da haben also Autoren und Mitarbeiter der Bibliothek ein profundes Wissen über die Science-Fiction-Literatur und die größte Bibliothek ihrer Art im Hintergrund und seit mittlerweile einigen Jahren eine große Datenbank aufgebaut, was Autoren zu verschiedenen Themen schreiben.
Als jemand, der ich selbst weiß, wie viele Situationen ich durch gelesene Bücher interpretiere – Bilder aus diesen Büchern im Hinterkopf habe und mir immer wieder mal sagen muss, dass ein Roman nur bedingt real ist, glaube ich sofort, dass es nichts gibt, was so sehr Denkprozesse auslösen und Kreativität triggern kann, wie Romane. Der befreit das Hirn gerade vom strikt logisch-folgerichtigen Denken, verrückt die Perspektive etwas nach links oder oben, und schon öffnen sich vollkommen neue Gedankenwege. Die Idee ist so brillant, dass es überraschend ist, dass sie wirklich angenommen wird. Anscheinend wird sie das.
Mensch Maschine Normal
Und nachdem ich dann wieder im Zug saß und das erste Handy-Ticket meines Lebens gekauft hatte, fragte ich mich wieder. Ist diese Stadt – die mir in vieler Hinsicht – so unfassbar „normal“ vorkommt, vielleicht die große Ausnahme? Sind die Musicaldarsteller, die mit „dem Alex“ [Alexander Klaws] telefonieren, normal? Die Menschen im Ministerium? Die größten Jules-Verne-Experten des Landes, die alle noch einen anderen Brotjob haben? Oder eher die Normalität vieler Menschen, die darin besteht, am Ende des Monats zu überlegen, wie denn die letzten 10 Tage mit dem leeren Konto noch überbrückt werden können?
Brauschweig ist die verstädterte Mensch-Maschine-Kopplung. In seiner Normalität sicher schon wieder ein Ausnahmefall in Deutschland. Aber ich sah die Zukunft: sie sitzt in einer Bibliothek in Wetzlar und liest Science-Fiction-Romane.
Auch zu Schwimmbädern ein schönes Minkmar-Zitat aus dem Mit-dem-Kopf-durch-die-Welt.Buch:
„Nichts gegen das große Geld und die wenigen, die es genießen können, aber die Stärke mitteleuropäischer Gesellschaften liegt gerade in der Mischung. Für Reiche ist es in Singapur, Russland und Malaysia ideal. […]Glaspaläste und Shopping Malls gibt es auf der ganzen Welt, bald vermutlich auch unter Wasser und auf dem Mond. Öffentliche Freibäder, Stadtteilfeste oder Fußgängerzonen, in denen sich Reiche und Arme, Helle und Dunkle, Christen und Muslime mit ihren Kindern vergnügen und drängeln, gibt es nur hier. Ich fand es immer erstaunlich, dass es in Algerien beispielsweise keine öffentlichen Schwimmbäder gibt oder dass man in den USA oder in Brasilien Mitglied in einem Club werden muss. Das ist eine teure und in vieler Hinsicht sozial sehr voraussetzungsreiche Angelegenheit, nur um mit den Kindern mal schwimmen zu gehen, es sei denn natürlich, jeder hat seinen eigenen Pool im Garten, was, für mich zumindest, wie eine Definition von struktureller Langeweile klingt.“ (s. 104)
*Dieser Post enthält Affiliate Links zu geniallokal. Es handelt sich dabei um Werbung. Ich bekomme eine kleine Provision, wenn ihr dort bestellt, und ihr habt bei den Guten bestellt.
I still remember the time when real life meetings for Wikipedians were new and adventurous and a bit scary. Did one really want to meet these strange other people from the Internet? How would they be? Could they even talk in real life or would they just sit behind a laptop screen staring on it for hours?
My first meeting in Hamburg – THE first Wikipedia meeting in Hamburg - would consist of three people (Hi Anneke, Hi Baldhur!) sitting in a pub, and just waiting and seeing what would happen. These meetings were kind of improvised, in a pub, quite private and personal in nature and no talk about projects, collaborations, “the movement” whatever. Just Wikipedia and Wikipedians having a nice evening.
So what a fitting setting to celebrate this day in Berlin just the old school way. Half improvised, organized by our dearest local troll user:Schlesinger on a talk page, we met in a pub, it was not clear who would come and what would happen except some people having a good time.
And so It was. In the “Matzbach” in the heart of Berlin-Kreuzberg seven people promised to come, in the end we were almost twenty. Long time Wikipedians, long-time-no-see-Wikipedians, a Wikipedian active mostly in Polish and Afrikaans, some newbies and two and a half people from Wikimedia Deutschland. Veronica from Wikimedia Deutschland brought a tiny but wonderful home-baked cake, and we just talked and laughed, talked about history and future. Actually, mostly we talked about future.
About the Wikipedian above 30, who has just started a new a university degree in archaeology, the question whether the Berlin community should have its own independent space, industrial beer, craft beer and the differences, the district of Berlin-Wedding, the temporary David-Bowie-memorial in Berlin-Schöneberg, the vending machine for fishing bait in Wedding, new pub meet-ups in the future, who should come to the open editing events, how to work better with libraries, colorful Wikipedians who weren’t there, looking for a new flat, whether perfectionism is helpful or rather not when planning something for Wikipedians, explaining Wikipedia to the newbie, the difficulties of cake-cutting and whatsoever.
No frustration, almost no talk about meta and politics, just Wikipedians interested in the world, Wikipedia and eager to be active in and for Wikipedia and with big plans for the future. Old school. So good.
Crossposting eines Posts von mir aus demWikipedia Kurier. Erfahrungsgemäß lesen das dort und hier ja doch andere Menschen.
Wikipedistas kommen und gehen. Manchmal gehen mehr, manchmal weniger. Einzelne davon fallen durch ihr Wirken in der gesamten Wikipedia auf oder versuchen sich wenigstens durch einen spektakulären Abgang in Szene zu setzen. Die meisten Autoren und Autorinnen aber gehen genauso still und leise wie sie gekommen sind und gearbeitet haben.
Die unseligen Autorenschwund-Debatten der unseligen Wikimedias kümmern sich ja um Zahlen und nicht um Autorinnen und Autoren. Wie armselig! Den Meta-aktiven Communitymitgliedern - aka Wikifanten - fallen vor allem die anderen Wikifanten auf, die entschwanden. Dabei zeigt sich bei genauerer Betrachtung, dass es um lauter einzelne Individuen mit verschiedenen Vorlieben, Arbeitsstilen und Interessen geht, die in Wikipedia tätig waren und sind. Es gibt vor allem diejenigen, die kommen, einen Beitrag leisten und dann wieder verschwinden. Der größte Teil der tatsächlichen Wikipedia wird von Menschen und Accounts gestaltet, deren Edits fast nur im Artikelnamensraum aufzufinden sind. Manchmal arbeiten sie unermütlich über viele Jahre, manchmal auch nur einige Wochen an einen oder zwei Artikeln. Viele davon sind als IP aktiv, so dass sich fast nichts über sie sagen lässt. Vielleicht sind die Beitragenden per IP auch gar nicht viele, sondern eine einzige sehr fleißige Autorin? Wer weiß?
Viele Wikipedianerinnen und Wikipedianer sind derzeit inaktiv.
Anlässlich des Projektes WikiWedding und in meinem Bestreben möglichst viele Wedding-Aktive daran zu beteiligen, lese ich ja derzeit viele Artikel zu einem Themengebiet, das mir in den letzten Jahren eher fremd war und an dessen Entstehung ich nicht beteiligt war. Wer sich in den letzten Monaten am Thema beteiligt hat, ist mir bewusst, wer sich von 2001 bis 2014 des Weddings angenommen hat, musste ich nachlesen. Eine spannende Lektüre voller mir unbekannter Namen und Accounts. Neben einigen mir bekannten Wikipedistas waren dort vor allem mir unbekannte Accounts. Accounts, die oft aufgehört haben zu editieren. Meist sind sie still und leise gegangen. Ihre Edits und Kommentare geben keinen Hinweis warum. Aber anscheinend war es anderswo schöner. Oder sie hatten den Einruck, alles in Wikipedia geschrieben zu haben, was sie beitragen wollten. Um diesen Autorinnen und Autoren zumindest nachträglich etwas Aufmerksamkeit zu geben, um ihre Namen kurz aus den Tiefen der Versionsgeschichten zu retten, sollen hier einfach einige Autorinnen(?) und Autoren gewürdigt werden, die sich um den Wedding in Wikpedia bemühten bevor sie verschwanden.
Da ist zum Beispiel der Artikel zur Chausseestraße. Ein Mammutwerk von Gtelloke, dessen Wikipedia-Edits sich von Juni bis Dezember 2012 fast ausschließlich auf diesen Artikel beschränkten.
Bild: Die Chausseestraße 114-118 in Richtung Invalidenstraße von Gtelloke
Da ist der Artikel zum Wedding selber. Angelegt 2002 von Otto, dessen letzter Edit aus dem Dezember 2004 stammt. Im November 2004 dann maßgeblich ausgebaut von Nauck, der sich auch sonst dem Ortsteil und seinen Themen widmete. Artikel zu Moabit, den Meyerschen Höfen, Mietskasernen und Schlafgängern waren Teil seines kurzen Werks, das im Wesentlichen nur zwei Wochen im November 2004 dauerte, aber die Grundlagen wichtiger Artikel zur Berliner Sozialgeschichte legte. Ein Blick auf seine Benutzerseite zeigt auch den Geist der Wikipedia-Frühzeit: ''GNU rockt! Der König ist tod, lang lebe das Volk! Lang lebe die Anarchie des Netzes! Licht und Liebe''
Weiterer Ausbau erfolgte durch 87.123.84.64, auch zu wikipedianischen Urzeiten. Dann passierte 500 Edits und acht Jahre im Wesentlichen nichts – mal ein Halbsatz hier, mal die Hinzufügung von drei Bahnstrecken dort, Hinzufügen und Löschen von berühmten Persönlichkeiten bis im Dezember 2014 der erste heute noch aktive Wikipedianer hinzukommt: Fridolin freudenfett verpasst dem Artikel mit „Katastrophalen Artikel etwas verbessert)“ eine Generalüberholung.
Der Leopoldplatz; angelegt von Frerix, der in den immerhin fünf Jahren seiner Wikipedia-Aktivität nie auch nur eine Benutzerseite für nötig hielt und anscheinend auch in keine Diskussion verwickelt wurde. Zu seinen wenigen Beiträgen gehören neben der Anlage des Leopoldplatzes auch noch die Anlage der englischen Stadt Sandhurst, die Anlage des Kreuzviertels in Münster und des Three Horses Biers. Dann war er/sie wieder weg. Mutter des Artikels ist hier aber 44Pinguine, die den heutigen Inhalt maßgeblich prägt und auch heute noch aktiv ist.
Nichts war für die Entwicklung des Weddings wohl so entscheidend wie die Geschichte der AEG. Dieser Artikel stammte in seiner Frühzeit von WHell, engagiertem Wikifanten, mit ausführlicher Artikelliste und Diskussionsseite, der uns 2007 verließ. Der letzte Eintrag auf seiner Diskussionsseite war „Hallo WHell, ich möchte Dich als den Hauptautor darüber informieren, dass ich den Artikel John Bull (Lokomotive) in die Wiederwahl zum Exzellenten Artikel gestellt habe,“ Größere Beiträge zur WEG folgten in den späteren Jahren durch Peterobst – aktiv von Februar bis April 2006 vor allem mit Beiträgen zur Berliner Industriegeschichte, nach seiner Benutzerseite AEG-Kenner und in Arbeit an einem Buch über den Konzern. Es folgten 80.226.238.197, von Georg Slickers 2006 (auch heute noch aktiv, wenn auch recht unregelmäßig), Flibbertigibbet 2006 , 79.201.110.89 im Jahr 2008 und der unermüdlichen 44Pinguine. Weiter ausgebaut von Onkel Dittmeyer, aktiv von 2009 bis Juli 2015 in Technikthemen und vielleicht immer noch unter neuem Account? Begann seine Karrier mit der Nutzerseite „Hier ist Nichts und das soll so bleiben !“ und hielt sich im Wesentlichen daran.
Da ist der Volkspark Rehberge. Angelegt von Ramiro 2005, aktiv 2005/2006, vor allem zum Thema Fußball. Maßgeblich ausgebaut, umfassend überarbeitet 2007 von 84.190.89.208 und noch einmal 2010 stark erweitert von Katonka. Landschaftsplaner mit unregelmäßigen Edits zwischen 2009 und 2014, die Edits waren wenige, aber die Qualität war hoch.
Bild: LSG-6 Volkspark Rehberge Berlin Mitte - Panoramabild auf die Wiesen des Volkspark Rehberge in Berlin, Wedding (Mitte). Von: Patrick Franke Lizenz: CC-BY-SA 3.0
Neben diesen Verschwundenen tauchen glücklicherweise aber auch heute noch aktive Wikifanten auf. Immer wieder 44Pinguine und Fridolin freudenfett. Darüber hinaus Definitiv, Magadan, Flibbertigibbet und Jo.Fruechtnicht.
Die Artikel entstanden durch Wikifanten und IPs. Accounts mit nur einem Thema oder anderen, die über Jahre thematisch sprangen. Während in der Frühzeit aber viele verschiedene Accounts und IPs an den Artikel beteiligt waren, waren in den letzten Jahren deutlich weniger Menschen aktiv. Fast alle inhaltlichen Edits in den von mir angesehenen Artikeln verteilen sich auf 44Pinguine, Fridolin freudenfett und Definitiv. Wikipedia wird kleiner und noch lebt sie. Aber wir können all‘ den Verschwundenen danken, die vor uns kamen.
Seit nun schon ein paar Jahren hört man immer wieder über Probleme in der kroatischen (und zu einem gewissen Grad auch der serbischen) Wikipedia. Rechte Gruppen sollen das Projekt übernommen haben und alle Wikipedianer, die nicht ihrer Meinung sind, rausgeekelt oder einfach gesperrt haben.
Lange war nichts passiert, aber seit Ende letzten Jahres sah sich die WMF dann doch mal die Situation an und es wurde schon zumindest ein Admin gebannt.
Nun hat die WMF ein Abschlußdokument veröffentlicht; oder genauer schon Mitte Juni und ich habe es erst heute bei reddit gesehen. In dem Dokument finden sich solche Perlen, als das in hrwp behauptet wurde, Nazi-Deutschland habe Polen überfallen weil Polen einen Genozid an Deutschen verübt hätten.
Der ganze Bericht kann hier gefunden werden. Mich macht die ganze Geschichte sowohl traurig als auch wütend. Wikipedia soll die Leute so gut es geht aufklären und nicht Propaganda verbreiten!
Ich habe heute dieses Blog auf einen neuen Server umgezogen, sein DNS aktualisiert und sein SSL repariert. Werde versuchen, es nun wieder öfters zu befüllen. Wünscht mir Glück 🙂.
Bereits seit gestern und noch bis zum 28. April laufen die Oversighter-Wahlen. Doc Taxon, User:He3nry und Nolispanmo treten zur Wiederwahl an. Ich wünsche: Viel Erfolg!
Eine der schöneren unbekannten Ecken der Wikipedia ist die Seite zur Auskunft. Dort können Menschen mögliche und unmögliche Fragen stellen, die dann mal launisch, mal larmoyant, mal ernsthaft oder auch gar nicht beantwortet werden. Wie im wahren Leben und eine ewige Fundgrube obskuren Wissens, seltsamer Fragestellungen und logischen Extremsports.
Nicht die DDR. Bild: Giorgio Conrad (1827-1889) - Mangiatori di maccheroni. Numero di catalogo: 102.
Dort nun fragte vor ein paar Tagen ein unangemeldeter Nutzer:
"Warum gab es in der DDR eigentlich nur Makkaroni (die in Wirklichkeit Maccheroncini waren), aber keine Spaghetti? Das erscheint mir nach Lektüre einiger Bücher aus der DDR so gewesen zu sein und ist mir auch so von meiner aus Ex-DDR-Bürgern bestehenden Verwandtschaft bestätigt worden. Warum?"
Es folgte eine längere und mäandernde ausgiebige Diskussion, die immerhin folgendes ergab:
* Anscheinend gab es in der DDR Spaghetti, zumindest erinnerten sich einige der Diskutanten an derartige Kindheitserlebnisse.
* Ob Spaghetti so verbreitet waren wie Makkaroni oder Spirelli, darüber bestand Uneinigkeit.
* Die Nudelsaucensituation war in Berlin besser als im Rest der DDR.
* Die DDR allgemein pflegte in vielerlei Hinsicht traditionellere Essgewohnheiten als Westdeutschland, die Küche der DDR ähnelte in vielem mehr der deutschen Vorkriegsküche als dies für die westdeutsche Küche gilt.
* In Vorkriegszeiten waren Makkaroni verbreiteter als Spaghetti.
* Schon bei Erich Kästner wurden Makkaroni gegessen
* Der Makkaroni-Spaghetti turn im (west-)deutschen Sprachraum war Mitte der 1960er
* Schuld könnten wahlweise das mangelnde Basilikum, die mangelnde Tomatensauce, überhaupt mangelnde Kräuter, Italienreisen, Gastarbeiter, Miracoli oder auch was ganz anderes sein.
* Klarer Konsens im Rahme: Sahne gehört keineswegs in Sauce Carbonara!
Gab es in der DDR nicht: Miracoli. Bild: Miracoli-Nudeln mit Mirácoli-Soße von Kraft. Von: Brian Ammon, Lizenz: CC-BY-SA 3.0
Daneben tauchten eine ganze Menge Kindheitserinnerungen auf an exotische Spaghettimahlzeiten mit kleingeschnittenen Spaghetti, Ketchup-basierter Tomatensauce und anderen kulinarischen Exotika des geteilten Deutschlands.
Einige Antworten, viel mehr Fragen:
* seit wann wird in Deutschland überhaupt Pasta gegessen?
* wie lange schon ist Tomatensauce verbreitet?
* seit wann essen westdeutsche Spaghetti?
* Und wer ist Schuld? Die Gastarbeiter? Die Italienurlauber? Miracoli?
* Und wie kommen eigentlich die Löcher in die Makkaroni?
Also verließen wir dann erst einmal die Auskunft und die dortige Diskussion und betrieben etwas weitere Recherche. Das heimische "Kochbuch der Haushaltungs- und Kochschule des Badischen Frauenvereins", veröffentlicht 1913 in Karlsruhe, kennt sowohl Makkaroni wie auch Spaghetti. Ungewohnt für heute: die Makkaroni werden in "halbfingerlange Stückchen gebrochen" und dann 25 bis 30 Minuten gekocht.
Neben den diversen Makkaroni-Gerichten gibt es auch einmal Spaghetti. Die Priorität ist klar. Spaghetti werden erklärt als "Spaghetti ist eine Art feine Makkaronisorte. Beim Einkauf achte man darauf, daß sie nicht hohl sind"
Die "Basler Kochschule. Eine leichtfaßliche Anleitung zur bürgerlichen und feineren Kochkunst" von 1908 kennt keine Spaghetti aber diverse Gericht mit "Maccaronis". Darunter sogar schon die Variante "a la napolitaine" mit Tomatensauce.
Weitere Recherche. Weitere Erkenntnisse bringt das Buch "Meine Suche nach der besten Pasta der Welt: Eine Abenteuerreise durch Italien", das die Ankunft der Makkaroni in Deutschland auf das frühe 18. Jahrhundert verlegt. Die 1701 nachweisbaren "Macronen" waren wohl eher Lasagne, aber Anfang des 18. Jahrhunderts entstanden in Prag und Wien echte Makkaroni-Fabriken.
Die Pasta folgte anscheinend den jungen Männern der Grand Tour aus Italien in das restliche Europa. Bestimmt waren die Grand Tours für junge Männer, die mal etwas von der Welt sehen und klassische europäische Bildung mitbekommen sollten, die auf der Tour aber anscheinend nicht nur Statuen und Kirchen kennenlernten, sondern auch Pasta.
Der Macaroni. Der Hipster seiner Zeit. Bild: Philip Dawe: The Macaroni. A Real Character at the Late Masquerade, 1773.
In England gab es sogar einen eigenen Modestil Macaroni für exaltierte junge Männer - "a fashionable fellow who dressed and even spoke in an outlandishly affected and epicene manner". Die englische Wikipedia schreibt dazu lakonisch: "Siehe auch: Hipster. Metrosexuell." Komplett falsch wäre wohl auch die Assoziation zur Toskana-Fraktion nicht.
Nach diesen extravagant und auffallend auftretenden jungen Männern ist nun wiederum im Englischen der Macaroni penguin - auf deutsch der Goldschopfpinguin - benannt.
Makkaroni-Penguin. Benannt nach dem Stil, nicht nach den Nudeln. Bild: Macaroni Penguin at Cooper Bay, South Georgia von Liam Quinn, Lizenz: CC-BY-SA 2.0
Wie aber kommen nun die Löcher in die Makkaroni? Und seit wann? Licht in dieses Dunkel bringt die "Encyclopedia of Pasta." Diese lokalisiert die Entstehung der maschinellen Pastafertigung - die für Makkaroni in zumutbarer Menge unvermeidlich ist - in die Bucht von Neapel in das 16. Jahrhundert. Dort existerte eine Heimindustrie mit Mühlen, an die sich relativ problemlos eine im 16. Jahrhundert aufkommende ’ngegno da maccarun anschließen lies, die es den Neapolitanern ersparte stundenlang im Teig herumzulaufen, um ihn zu kneten: im Wesentlichen Holzpressen mit einem Einsatz aus Kupfer, je nach Form des Einsatzes entstehen verschiedene Nudelsorten und damit unter anderem Makkaroni. Die Makkaroni wurden dann in langen Fäden zum trocknen in die süditalienische Sonne gehängt.
Neapel, 19. Jahrhundert. Bild: Giorgio Sommer (1834-1914), "Torre Annunziata-Napoli - Fabbrica di maccheroni". Fotografia colorita a mano. Numero di catalogo: 6204.
Das hat alles nicht mehr wirklich etwas mit Spaghetti und der DDR zu tun, beantwortet nicht, warum die Deutschen in den 1960ern plötzlich lieber Spaghetti als Makkaroni mochten, oder warum die Makkaroni bei ihrem ersten Zug über die Alpen die Tomatensauce in der Schweiz ließen? Warum gibt es in Deutschland kein Äquivalent zu "Macaroni and cheese" (mehr)? Gab es ein Miracoli-Äquivalent in der DDR, bei dem es Pasta, Sauce und Käse schon in einer Packung gab? Warum sind Makkaroni in Deutschland tendenziell lang und dünn in vielen anderen Ländern aber dicker und hörnchenförmig-gebogen? Es ist hochspannend. Und ein Grund, noch viel mehr zu recherchieren.
Seit 2019 wählt das Wikiversum die coolsten Tools, die besten Hilfsmittel, um in Wikipedia und anderen Wikis zu werken. Eines davon ist der Pywikibot, der Bot aller Bots.
Schneeregen fegte waagerecht über Vorplatz des Tempelhofer Hafens. Mein Pullover war gar nicht so kuschlig und dicht wie ich ihn in Erinnerung hatte. Die Handschuhe waren im Laufe der Jahre so fadenscheinig geworden, dass eine einzelne kurze Radtour die Finger vereisen ließ.
Ein einsamer, von Weihnachten übrig gebliebener, Quarkkeulchen-Stand vor dem Tempelhofer Hafen. Seine Lichter verhießen Wärme. Der Weg dorthin: Von Entbehrungen gezeichnet. Der Wind, der einem aus allen Richtungen ins Gesicht blies, trieb die Leute davon. Sie wussten nicht wohin, denn alles war geschlossen und zu Hause wollten sie ihre Mitbewohner nicht mehr sehen. Über der Szene kreiste ein hungriger Taubenschwarm.
„Ist es nicht herrlich“, fragte ich DJ Hüpfburg. „So viel Platz! Fast das ganze Hafengelände gehört uns. Und wir können uns problemlos aus drei Meter Sicherheitsabstand anschreien.“ – Sie antwortete „Du spinnst. Es ist scheißkalt. Ich bibbere. Das letzte Mal, als ich so gefroren habe, bin ich im Rozbrat mit meiner ehemaligen Band aufgetreten: „Pierdzące Zakonnice“.
Wir spielten Prog-Punk. Kein Wasser, keine Heizung und ein sibirischer Windhauch kam aus Richtung Minsk. Wer auf Toilette wollte, hat einen Eispickel in die Hand bekommen, falls das Plumpsklo wieder zugefroren war. Und am Ende des Abends haben wir Wahlplakate im Konzertsaal verbrannt, um nicht ganz zu erfrieren.
Aber wir haben gerockt: Kasia an der Geige, die andere Kasia am Theremin, ich an der KitchenAid und Anna am Gong und an der Rezitation. So viel Kunst war nie wieder davor oder danach im Rozbrat. Leider war es den Pferden zu kalt, so dass die weiße Kutsche ausgefallen ist. Hier am Hafen ist keine Kunst. Hier ist es nur scheißkalt. Ich gehe.“
Später, im Chat. Hüpfburgs Schilderung hatte mich an ein Video erinnert, das ich kurz vorher gesehen hatte: „Wikimedia Coolest Tool Award 2020.“ in meinen Versuchen, DJ Hüpfburg für die Wikipedia und ihr Umfeld zu begeistern, postete ich ihr den Link.
Southgeist: Aber Tools. Nur mit ausgewählten Menschen. Fast nur Technik und kreative Sachen.
Hüpfburg: Wikipedia spießerfrei? Du meinst, das soll gehen?
Southgeist: Schau doch mal.
Hüpfburg: Ich sehe jetzt schon drei Minuten lang Berliner Straßen ohne Ton. Ich dachte schon, meine Lautsprecher wären kaputt.
Hüpfburg: I like the music.
Southgeist: Eben. Warte erst auf die Tools.
Hüpfburg: 52 Minuten! So lange soll ich Wikipedia schauen? In der Zeit zerstöre ich zwei Ehen, bringe einen Priester vom Glauben ab und bringe drei Paare neu zueinander. Sage mir lieber, was für Tools vorkommen.
Die coolest Tools
Ich erzählte.
Im Video werden vorgestellt: Der AutoWikiBrowser (Hüpfburg: „Da klingt der Name schon langweilig“), SDZeroBot generiert Benutzerseitenreports („Mich interessieren weder Benutzer noch ihre Seiten“), Proofread Page Extension („Korrekturlesen, geht es noch spießiger?“), Listen to Wikipedia („Schön, aber reichlich Kitsch. Wenn eines Tages zwei Wikipedianer kommen und einander heiraten wollen, werde ich das Tool in den Event integrieren“), AbuseFilter („Zu sehr Polizei“), LinguaLibre („I like“), und Pywikibot – ein Tool zum Erstellen weiterer Tools. („Das klingt spannend – erzähle mir mehr.“)
Pywikibot
Pywikibot ist ein Framework zum Erstellen von Bots. Oder anders gesagt: wer sich den Pywikibot installiert, kann mit überschaubarem Aufwand eigene Bots schaffen. Oder sich an einem der bereits auf dieser Basis geschaffenen Skripte bedienen. Die Bots können prinzipiell alles, was menschliche Nutzer von MediaWiki-Wikis auch können – nur schneller.
Wobei können in diesem Zusammenhang natürlich bedeutet: jemensch muss dem Bot vorher sagen, was er tun soll. Das dauert länger als ein Edit. Der Bot kommt sinnvoll ins Spiel, wo es eine hohe Zahl gleichartiger Edits gibt. Zum Artikelschreiben ist das wenig – zum Anpassen von Formalien ist es super. Und dazwischen liegt ein Graubereich. Nicht alles ist sinnvoll, nicht alles ist erlaubt – und um die Kontrolle zu wahren, hat der Pywikibot einen automatischen Slow-Down-Mechanismus, der den Bot absichtlich ausbremst.
Pywikibot geht zurück auf verschiedene Bots und Skripte aus dem Jahr 2003, existiert in dieser Form seit etwa 2008. Die aktuelle Variante ist in und für Python 3 geschrieben. Die Community, die sich um das Framework kümmert, hat eine dreistellige Zahl von Mitgliedern und ist so international, wie es die frühe Wikipedia war. Rein aus dem Bauchgefühl heraus würde ich auch sagen, was Charaktertypen und Soziodemographie angeht, ist die Pywikibot-Gruppe sehr viel näher an der Ur-Wikipedia als die heutigen Wikipedistas.
DJ Hüpfburg: „Du sagst es. Alt-Wikipedia. Diese Tool-Awards sind solche Lebenswerkauszeichungen? Das Bot-Framework gibt es seit fast 20 Jahren, das Proofread-Tool existiert seit fast 15 Jahren. Ist der Award so langsam oder gibt es so wenig Neues?“
Ich glaube, der Award ist langsam. Beziehungsweise er existiert erst seit letztem Jahr. Jetzt muss er die ganzen Tools der letzten Jahrzehnte durchprämieren, damit die nicht vergessen werden. Wie bei der Wikipedia auch: Die Grundlagen wurden vor langer Zeit gelegt. Alles, was jetzt kommt, baut darauf an, verbessert, schafft aber nur selten fundamental Neues.
Change Musiker to Musiker*innen
„Außer dem Tool-Award. Der ist neu? Und dem Video nach zu urteilen reichlich großartig.“
Yup. Und er hat mir und dir den Pywikibot gelehrt und damit eine wichtige Aufgabe erfüllt.
DJ Hüpfburg: „Ich kann also auf Basis von Pywikibot alle ‚Musiker‘ in Wikipedia durch ‚Musiker*innen‘ ersetzen?“
Ich: „Theoretisch ja. Praktisch gibt es verschiedene Hindernisse. Und du wirst auf ewig gesperrt werden.“
DJ Hüpfburg: „Dachte ich. Noch so jung und schon so strukturkonservativ diese Website. Wäre sie ein Mensch, würde sie einen beigen Pullunder über weißem Hemd tragen und Leserbriefe an die Fernsehzeitschrift schreiben. Aber ich kann mein eigenes Wiki aufsetzen und da noch Herzenslust alles bot-mäßig umbauen?“
Ich: „Yup. Wikidata freut sich auch. Da gibt es noch viel zu tun und die sind superfreundlich dort.“
DJ Hüpfburg: „Ich auf meinem Pybot einreitend in Wikidata! Das wäre fast so gut wie im Rozbrat. Mit der Kutsche, die dann doch nicht kam. Irgendwann im Laufe des Abends spielten wir Mozart. Da haben die Squatter angefangen mit Äpfeln zu werfen. Wir uns hinter dem Gong geduckt und ich ein Kitchen-Aid-Solo. Ich erinnere mich noch an den einen Tänzer, der allein Stand und Luft-Küchenmaschine gespielt hat. Ein Arm angwickelt am Körper als würde er die Maschine an sich drücken, mit dem anderen weit ausholende Bewegungen, um dann auf dem Einschaltknopf zu laden.“
„Leider hatten wir dem Publikum einen Mozart-Schock versetzt und die wollten uns nicht mehr gehen. Dadurch hatten wir alle Auftrittsorte in Posen durch. Kasia ging nach Prag und Paris, Jazz-Theremin studieren. „Ein Juwel unter unserer Studentinnen“ sagte mal eine Professorin. Kasia wäre fast dieses Jahr in der Philharmonie aufgetreten. Aber Deine komische Wikipedia hat immer noch keinen Artikel von ihr.“
Ich: „Es ist nicht meine Wikipedia.“
Ruhe. Hüpfburg dachte.
„Dieser Bot. Der kann doch sicher in Wikidata alle Personen auslesen, die Theremin spielen. Und dann eine Liste in Wikipedia anlegen. Die regelmäßig erneuert wird. Das müsste doch gehen. Vielleicht ist es einen Versuch wert.“
















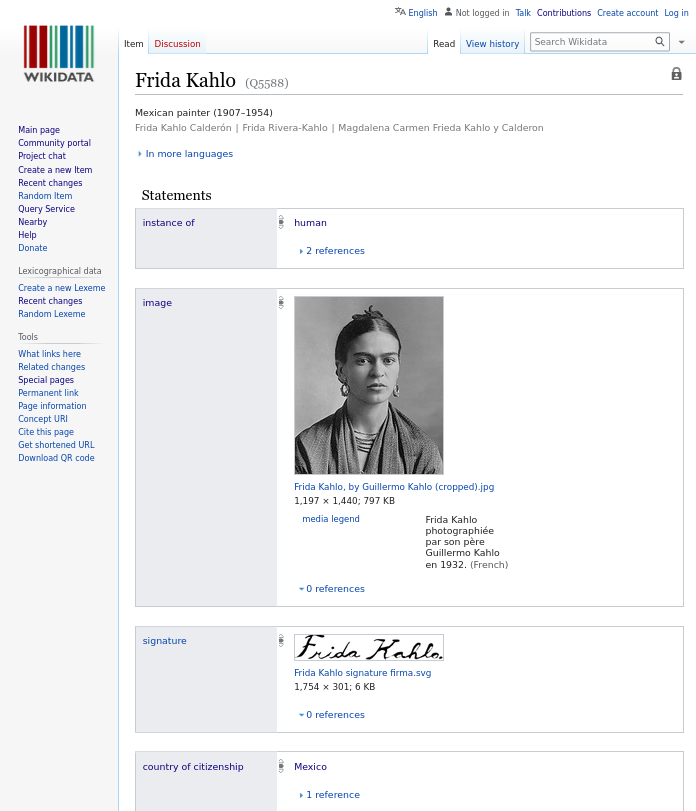












































_-_n._102_-_Scena_di_genere.jpg)

_-_02.jpg)
.jpg)
_-_n._6204_-_Napoli_-_Fabbrica_di_maccheroni.jpg)
{kind=link}
{kind=link}
{kind=link}
{kind=link}